05: Synthesizing Human Images [Q&A Session]
-
 Full Access
Full Access
-
 Onsite Student Access
Onsite Student Access
-
 Virtual Full Access
Virtual Full Access
Date/Time: 06 – 17 December 2021
All presentations are available in the virtual platform on-demand.
Barbershop: GAN-based Image Compositing using Segmentation Masks
Abstract: Seamlessly blending features from multiple images is extremely challenging because of complex relationships in lighting, geometry, and partial occlusion which cause coupling between different parts of the image. Even though recent work on GANs enables synthesis of realistic hair or faces, it remains challenging to combine them into a single, coherent, and plausible image rather than a disjointed set of image patches. We present a novel solution to image blending, particularly for the problem of hairstyle transfer, based on GAN-inversion. We propose a novel latent space for image blending, and propose an extension to existing GAN-inversion algorithms to align reference images to a single composite image. Our novel representation enables the transfer of the visual properties of reference images including specific details such as moles and wrinkles, and because we do image blending in a latent space we are able to synthesize images that are coherent. Our approach avoids blending artifacts present on other approaches and finds a globally consistent image. Our results demonstrate a significant improvement over the current state of the art in a user study, with users preferring our blending solution over 95 percent of the time.
Author(s)/Presenter(s):

EyelashNet: A Dataset and A Baseline Method for Eyelash Matting
Abstract: Eyelashes play a crucial part in the human facial structure and largely affect the facial attractiveness in modern cosmetic design. However, the appearance and structure of eyelashes can easily induce severe artifacts in high-fidelity multi-view 3D face reconstruction. Unfortunately it is highly challenging to remove eyelashes from portrait images using both traditional and learning-based matting methods due to the delicate nature of eyelashes and the lack of eyelash matting dataset. To this end, we present EyelashNet, the first eyelash matting dataset which contains 5,400 high-quality eyelash matting data captured from real world and 5,272 virtual eyelash matting data created by rendering avatars. Our work consists of a capture stage and an inference stage to automatically capture and annotate eyelashes instead of tedious manual efforts. The capture is based on a specifically-designed fluorescent labeling system. By coloring the eyelashes with a safe and invisible fluorescent substance, our system takes paired photos with colored and normal eyelashes by turning the equipped ultraviolet (UVA) flash on and off. We further correct the alignment between each pair of photos and use a novel alpha matte inference network to extract the eyelash alpha matte. As there is no prior eyelash dataset, we propose a progressive training strategy that progressively fuses captured eyelash data with virtual eyelash data to learn the latent semantics of real eyelashes. As a result, our method can accurately extract eyelash alpha mattes from fuzzy and self-shadow regions such as pupils, which is almost impossible by manual annotations. To validate the advantage of EyelashNet, we present a baseline method based on deep learning that achieves state-of-the-art eyelash matting performance with RGB portrait images as input. We also demonstrate that our work can largely benefit important real applications including high-fidelity personalized avatar and cosmetic design.
Author(s)/Presenter(s):

Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control
Abstract: We propose Neural Actor (NA), a new method for high-quality synthesis of humans from arbitrary viewpoints and under arbitrary controllable poses. Our method is developed upon recent neural scene representation and rendering works which learn representations of geometry and appearance from only 2D images. While existing works demonstrated compelling rendering of static scenes and playback of dynamic scenes, photo-realistic reconstruction and rendering of humans with neural implicit methods, in particular under user-controlled novel poses, is still difficult. To address this problem, we utilize a coarse body model as the proxy to unwarp the surrounding 3D space into a canonical pose. A neural radiance field learns pose-dependent geometric deformations and pose- and view-dependent appearance effects in the canonical space from multi-view video input. To synthesize novel views of high fidelity dynamic geometry and appearance, NA leverages 2D texture maps defined on the body model as latent variables for predicting residual deformations and the dynamic appearance. Experiments demonstrate that our method achieves better quality than the state-of-the-arts on playback as well as novel pose synthesis, and can even generalize well to new poses that starkly differ from the training poses. Furthermore, our method also supports shape control on the free-view synthesis of human actors.
Author(s)/Presenter(s):
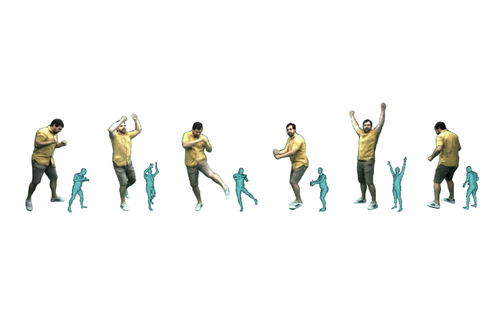
Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
Abstract: We present an algorithm for re-rendering a person from a single image under arbitrary poses. Existing methods often have difficulties in hallucinating occluded contents photo-realistically while preserving the identity and fine details in the source image. We first learn to inpaint the correspondence field between the body surface texture and the source image with a human body symmetry prior. The inpainted correspondence field allows us to transfer/warp local features extracted from the source to the target view even under large pose changes. Directly mapping the warped local features to an RGB image using a simple CNN decoder often leads to visible artifacts. Thus, we extend the StyleGAN generator so that it takes pose as input (for controlling poses) and introduces a spatially varying modulation for the latent space using the warped local features (for controlling appearances). We show that our method compares favorably against the state-of-the-art algorithms in both quantitative evaluation and visual comparison.
Author(s)/Presenter(s):

SketchHairSalon: Deep Sketch-based Hair Image Synthesis
Abstract: Recent deep generative models allow real-time generation of hair images from sketch inputs. Existing solutions often require a user-provided binary mask to specify a target hair shape. This not only costs users extra labor but also fails to capture complicated hair boundaries. Those solutions usually encode hair structures via orientation maps, which, however, are not very effective to encode complex structures. We observe that colored hair sketches already implicitly define target hair shapes as well as hair appearance and are more flexible to depict hair structures than orientation maps. Based on these observations, we present SketchHairSalon, a two-stage framework for generating realistic hair images directly from freehand sketches depicting desired hair structure and appearance. At the first stage, we train a network to predict a hair matte from an input hair sketch, with an optional set of non-hair strokes. At the second stage, another network is trained to synthesize the structure and appearance of hair images from the input sketch and the generated matte. To make the networks in the two stages aware of long-term dependency of strokes, we apply self-attention modules to them. To train these networks, we present a new moderately large dataset, containing diverse hairstyles with annotated hair sketch-image pairs and corresponding hair mattes. Two efficient methods for sketch completion are proposed to automatically complete repetitive braided parts and hair strokes, respectively, thus reducing the workload of users. Based on the trained networks and the two sketch completion strategies, we build an intuitive interface to allow even novice users to design visually pleasing hair images exhibiting various hair structures and appearance via freehand sketches. The qualitative and quantitative evaluations show the advantages of the proposed system over the existing or alternative solutions.
Author(s)/Presenter(s):