

09. Neural Rendering [Q&A Session]
-
 Full Access
Full Access
-
 Onsite Student Access
Onsite Student Access
-
 Virtual Full Access
Virtual Full Access
Date/Time: 06 – 17 December 2021
All presentations are available in the virtual platform on-demand.
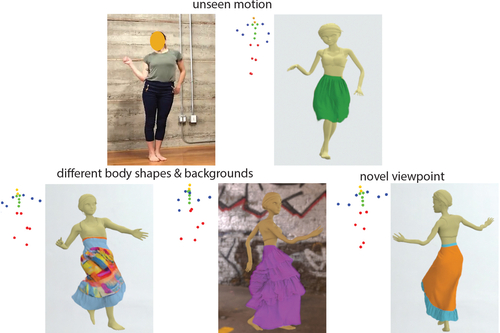
Dynamic Neural Garments
Abstract: A vital task of the wider digital human effort is the creation of realistic garments on digital avatars, both in the form of characteristic fold patterns and wrinkles in static frames as well as richness of garment dynamics under avatars' motion. Existing workflow of modeling, simulation, and rendering closely replicates the physics behind real garments, but is tedious and requires repeating most of the workflow under changes to characters' motion, camera angle, or garment resizing. Although data-driven solutions exist, they either focus on static scenarios or only handle dynamics of tight garments. We present a solution that, at test time, takes in body joint motion to directly produce realistic dynamic garment image sequences. Specifically, given the target joint motion sequence of an avatar, we propose dynamic neural garments to synthesize plausible dynamic garment appearance from a desired viewpoint. Technically, our solution generates a coarse garment proxy sequence, learns deep dynamic features attached to this template, and neurally renders the features to produce appearance changes such as folds, wrinkles, and silhouettes. We demonstrate generalization behavior to both unseen motion and unseen camera views. Further, our network can be fine-tuned to adopt to new body shape and/or background images. We demonstrate our method on a wide range of real and synthetic garments. We also provide comparisons against existing neural rendering and image sequence translation approaches, and report clear quantitative and qualitative improvements.
Author(s)/Presenter(s):
HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields
Abstract: Neural Radiance Fields (NeRF) are able to reconstruct scenes with unprecedented fidelity, and various recent works have extended NeRF to handle dynamic scenes. A common approach to reconstruct such non-rigid scenes is through the use of a learned deformation field mapping from coordinates in each input image into a canonical template coordinate space. However, these deformation-based approaches struggle to model changes in topology, as topological changes require a discontinuity in the deformation field, but these deformation fields are necessarily continuous. We address this limitation by lifting NeRFs into a higher dimensional space, and by representing the 5D radiance field corresponding to each individual input image as a slice through this ``hyper-space''. Our method is inspired by level set methods, which model the evolution of surfaces as slices through a higher dimensional surface. We evaluate our method on two tasks: (i) interpolating smoothly between "moments", i.e., configurations of the scene, seen in the input images while maintaining visual plausibility, and (ii) novel-view synthesis at fixed moments. We show that our method, which we dub HyperNeRF, outperforms existing methods on both tasks. Compared to Nerfies, HyperNeRF reduces average error rates by 4.1% for interpolation and 8.6% for novel-view synthesis, as measured by LPIPS.
Author(s)/Presenter(s):

NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination
Abstract: We address the problem of recovering the shape and spatially-varying reflectance of an object from multi-view images (and their camera poses) of an object illuminated by one unknown lighting condition. This enables the rendering of novel views of the object under arbitrary environment lighting and editing of the object’s material properties. The key to our approach, which we call Neural Radiance Factorization (NeRFactor), is to distill the volumetric geometry of a Neural Radiance Field (NeRF) [Mildenhall et al. 2020] representation of the object into a surface representation and then jointly refine the geometry while solving for the spatially-varying reflectance and environment lighting. Specifically, NeRFactor recovers 3D neural fields of surface normals, light visibility, albedo, and Bidirectional Reflectance Distribution Functions (BRDFs) without any supervision, using only a re-rendering loss, simple smoothness priors, and a data-driven BRDF prior learned from real-world BRDF measurements. By explicitly modeling light visibility, NeRFactor is able to separate shadows from albedo and synthesize realistic soft or hard shadows under arbitrary lighting conditions. NeRFactor is able to recover convincing 3D models for free-viewpoint relighting in this challenging and underconstrained capture setup for both synthetic and real scenes. Qualitative and quantitative experiments show that NeRFactor outperforms classic and deep learning-based state of the art across various tasks. Our videos, code, and data are available at people.csail.mit.edu/xiuming/projects/nerfactor/.
Author(s)/Presenter(s):

Neural Frame Interpolation for Rendered Content
Abstract: The demand for creating rendered content continues to drastically grow. As it often is extremely computationally expensive and thus costly to render high-quality computer-generated images, there is a high incentive to reduce this computational burden. Recent advances in learning-based frame interpolation methods have shown exciting progress but still have not achieved the production-level quality which would be required to render fewer pixels and achieve savings in rendering times and costs. Therefore, in this paper we propose a method specifically targeted to achieve high-quality frame interpolation for rendered content. In this setting, we assume that we have full input for every n-th frame in addition to auxiliary feature buffers that are cheap to evaluate (e.g. depth, normals, albedo) for every frame. We propose solutions for leveraging such auxiliary features to obtain better motion estimates, more accurate occlusion handling, and to correctly reconstruct non-linear motion between keyframes. With this, our method is able to significantly push the state-of-the-art in frame interpolation for rendered content and we are able to obtain production-level quality results.
Author(s)/Presenter(s):

