Technical Papers Presentations
-
 Full Access
Full Access
-
 Onsite Student Access
Onsite Student Access
-
 Virtual Full Access
Virtual Full Access
Date/Time: 06 – 17 December 2021
All presentations are available in the virtual platform on-demand.
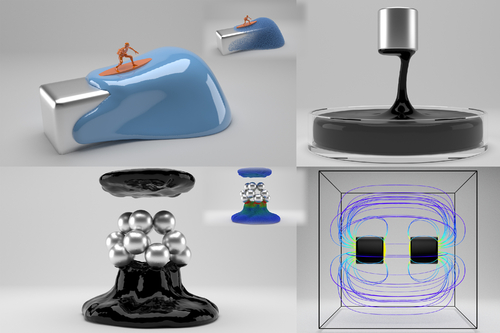
A Material Point Method for Nonlinearly Magnetized Materials
Abstract: We propose a novel numerical scheme to simulate interactions between a magnetic field and nonlinearly magnetized objects immersed in it. Under our nonlinear magnetization framework, the strength of magnetic forces is effectively saturated to produce stable simulations without requiring any hyper-parameter tuning. The mathematical model of our approach is based upon Langevin’s nonlinear theory of paramagnetism, which bridges microscopic structures and macroscopic equations after a statistical derivation. We devise a hybrid Eulerian-Lagrangian numerical approach to simulating this strongly nonlinear process by leveraging the discrete material points to transfer both material properties and the number density of magnetic micro-particles in the simulation domain. The magnetic equations can then be built and solved efficiently on a background Cartesian grid, followed by a finite difference method to incorporate magnetic forces. The multi-scale coupling can be processed naturally by employing the established particle-grid interpolation schemes in a conventional MLS-MPM framework. We demonstrate the efficacy of our approach with a host of simulation examples governed by magnetic-mechanical coupling effects, ranging from magnetic deformable bodies to magnetic viscous fluids with nonlinear elastic constitutive laws.
Author(s)/Presenter(s):
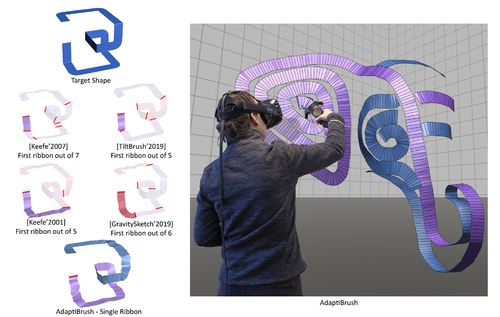
AdaptiBrush: Adaptive General and Predictable VR Ribbon Brush
Abstract: Virtual reality drawing applications let users draw 3D shapes using brushes that form ribbon shaped, or ruled-surface, strokes. Each ribbon is uniquely defined by its user-specified ruling length, path, and the ruling directions at each point along this path. Existing brushes use the trajectory of a handheld controller in 3D space as the ribbon path, and compute the ruling directions using a fixed mapping from a specific controller coordinate-frame axis. This fixed mapping forces users to rotate the controller and thus their wrists to change ribbon normal or ruling directions, and requires substantial physical effort to draw even medium complexity ribbons. Since human ability to rotate their wrists continuously is limited, the space of ribbon geometry users can comfortably draw using these brushes is limited. These brushes can be unpredictable, producing ribbons with unexpectedly varying width or flipped and wobbly normals in response to seemingly natural hand gestures. Our AdaptiBrush ribbon brush system dramatically extends the space of ribbon geometry users can comfortably draw while enabling users to accurately predict the ribbon shape that a given hand motion produces. We achieve this by introducing a novel adaptive ruling direction computation method, enabling users to easily change ribbon ruling and normal orientation using predominantly translational controller, and thus wrist, motion. We facilitate ease-of-use by computing predictable ruling directions that smoothly change in both world and controller coordinate systems, and facilitate ease-of-learning by prioritizing ruling directions which are well-aligned with one of the controller coordinate system axes. Our comparative user studies confirm that our more general and predictable ruling computation leads to significant improvements in brush usability and effectiveness compared to all prior brushes; in a head to head comparison users preferred AdaptiBrush over the next-best brush by a margin of 2 to 1.
Author(s)/Presenter(s):
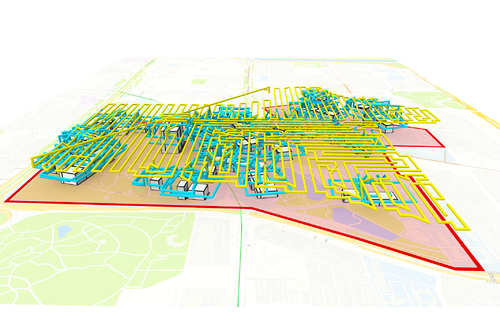
Aerial Path Planning for Online Real-Time Exploration and Offline High-Quality Reconstruction of Large-Scale Urban Scenes
Abstract: Existing approaches have shown that, through carefully planning flight trajectories, images captured by Unmanned Aerial Vehicles (UAVs) can be used to reconstruct high-quality 3D models for real environments. These approaches greatly simplify and cut the cost of large-scale urban scene reconstruction. However, to properly capture height discontinuities in urban scenes, all state-of-the-art methods require prior knowledge on scene geometry and hence, additional prepossessing steps are needed before performing the actual image acquisition flights. To address this limitation and to make urban modeling techniques even more accessible, we present a real-time explore-and-reconstruct planning algorithm that does not require any prior knowledge for the scenes. Using only captured 2D images, we estimate 3D bounding boxes for buildings on-the-fly and use them to guide online path planning for both scene exploration and building observation. Experimental results demonstrate that the aerial paths planned by our algorithm in real-time for unknown environments support reconstructing 3D models with comparable qualities and lead to shorter flight air time.
Author(s)/Presenter(s):
Aesthetic-guided Outward Image Cropping
Abstract: Image cropping is a commonly used post-processing operation for adjusting the scene composition of an input photography, therefore improving its aesthetics. Existing automatic image cropping methods are all bounded by the image border, thus have very limited freedom for aesthetics improvement if the original scene composition is far from ideal, e.g. the main object is too close to the image border. In this paper, we propose a novel, aesthetic-guided outward image cropping method. It can go beyond the image border to create a desirable composition that is unachievable using previous cropping methods. Our method first evaluates the input image to determine how much the content of the image should be extrapolated by a FOV evaluation model. We then synthesize the image content in the extrapolated region, and seek an optimal aesthetic crop within the expanded FOV, by jointly considering the aesthetics of the cropped view, and the local image quality of the extrapolated image content. Experimental results show that our method can generate more visually pleasing image composition in cases that are difficult for previous image cropping tools due to the border constraint, and can also automatically degrade to an inward method when high-quality image extrapolation is infeasible.
Author(s)/Presenter(s):

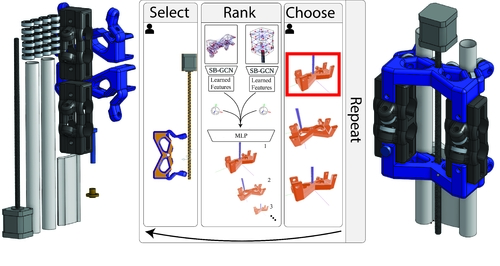
AutoMate: A Dataset and Learning Approach for Automatic Mating of CAD Assemblies
Abstract: Assembly modeling is a core task of computer aided design (CAD), comprising around one third of the work in a CAD workflow. Optimizing this process therefore represents a huge opportunity in the design of a CAD system, but current research of assembly based modeling is not directly applicable to modern CAD systems because it eschews the dominant data structure of modern CAD: parametric boundary representations (BREPs). CAD assembly modeling defines assemblies as a system of pairwise constraints, called mates, between parts, which are defined relative to BREP topology rather than in world coordinates common to existing work. We propose SB-GCN, a representation learning scheme on BREPs that retains the topological structure of parts, and use these learned representations to predict CAD type mates. To train our system, we compiled the first large scale dataset of BREP CAD assemblies, which we are releasing along with benchmark mate prediction tasks. Finally, we demonstrate the compatibility of our model with an existing commercial CAD system by building a tool that assists users in mate creation by suggesting mate completions, with 72.2% accuracy.
Author(s)/Presenter(s):
Barbershop: GAN-based Image Compositing using Segmentation Masks
Abstract: Seamlessly blending features from multiple images is extremely challenging because of complex relationships in lighting, geometry, and partial occlusion which cause coupling between different parts of the image. Even though recent work on GANs enables synthesis of realistic hair or faces, it remains challenging to combine them into a single, coherent, and plausible image rather than a disjointed set of image patches. We present a novel solution to image blending, particularly for the problem of hairstyle transfer, based on GAN-inversion. We propose a novel latent space for image blending, and propose an extension to existing GAN-inversion algorithms to align reference images to a single composite image. Our novel representation enables the transfer of the visual properties of reference images including specific details such as moles and wrinkles, and because we do image blending in a latent space we are able to synthesize images that are coherent. Our approach avoids blending artifacts present on other approaches and finds a globally consistent image. Our results demonstrate a significant improvement over the current state of the art in a user study, with users preferring our blending solution over 95 percent of the time.
Author(s)/Presenter(s):

Beyond Mie Theory: Systematic Computation of Bulk Scattering Parameters based on Microphysical Wave Optics
Abstract: Light scattering in participating media and translucent materials is typically modeled using the radiative transfer theory. Under the assumption of independent scattering between particles, it utilizes several bulk scattering parameters to statistically characterize light-matter interactions at the macroscale. To calculate these parameters based on microscale material properties, the Lorenz-Mie theory has been considered the gold standard. In this paper, we present a generalized framework capable of systematically and rigorously computing bulk scattering parameters beyond the far-field assumption of Lorenz-Mie theory. Our technique accounts for microscale wave-optics effects such as diffraction and interference as well as interactions between nearby particles. Our framework is general, can be plugged in any renderer supporting Lorenz-Mie scattering, and allows arbitrary packing rates and particles correlation; we demonstrate this generality by computing bulk scattering parameters for a wide range of materials, including anisotropic and correlated media.
Author(s)/Presenter(s):

Binaural Audio Generation via Multi-task Learning
Abstract: We present a learning-based approach to generate binaural audio from mono audio using multi-task learning. Our formulation leverages additional information from two related tasks: the binaural audio generation task and the flipped audio classification task. Our learning model extracts spatialization features from the visual and audio input, predicts the left and right audio channels, and judges whether the left and right channels are flipped. First, we extract visual features using ResNet from the video frames. Next, we perform binaural audio generation and flipped audio classification using separate subnetworks based on visual features. Our learning method optimizes the overall loss based on the weighted sum of the losses of the two tasks. We train and evaluate our model on the FAIR-Play dataset and the YouTube-ASMR dataset. We perform quantitative and qualitative evaluations to demonstrate the benefits of our approach over prior techniques.
Author(s)/Presenter(s):

Camera Keyframing with Style and Control
Abstract: In this work we present a tool that enables artists to synthesize camera motions following a learned camera behavior while enforcing user-designed keyframes as constraints along the sequence. To solve this motion in-betweening problem, we train a camera motion generator from a collection of trajectories using an additional conditioning on target keyframes. We also condition the generator with a style code automatically extracted from real film clips through the design of a gating LSTM network. This style code encodes the camera behavior defined as the correlation between the characters and camera motions. We further extend the system by incorporating a fine control of camera speed and direction via a hidden state mapping module. We then evaluate our method on two aspects: i) the capacity to synthesize camera trajectories by extracting camera behaviors from real movie film clips, and constraining them with user defined keyframes; ii) the capacity to ensure that in-between motions still comply with the reference camera behavior while satisfying the keyframe constraints. As a result, our system is the first behavior-aware keyframe in-betweening technique for camera control that balances behavior-driven automation with precise and interactive control.
Author(s)/Presenter(s):

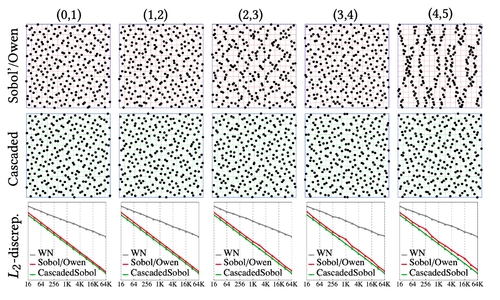
Cascaded Sobol' Sampling
Abstract: Rendering quality is largely influenced by the samplers used in Monte Carlo integration. Important factors include sample uniformity (e.g., low discrepancy) in the high-dimensional integration domain, sample uniformity in lower-dimensional projections, and lack of dominant structures that could result in aliasing artifacts. A widely used and successful construction is the Sobol' sequence that guarantees good high-dimensional uniformity and consequently results in faster convergence of quasi-Monte Carlo integration. We show that this sequence exhibits low uniformity and dominant structures in low-dimensional projections. These structures impair quality in the context of rendering, as they precisely occur in the 2-dimensional projections used for sampling light sources, reflectance functions, or the camera lens or sensor. We propose a new cascaded construction, which, despite dropping the sequential aspect of Sobol' samples, produces point sets exhibiting provably perfect dyadic partitioning (and therefore, excellent uniformity) in consecutive 2-dimensional projections, while preserving good high-dimensional uniformity. By optimizing the initialization parameters and performing Owen scrambling at finer levels of binary representations, we further improve over Sobol's integration convergence rate. Our method does not incur any overhead as compared to the generation of the Sobol' sequence, is compatible with Owen scrambling and can be used in rendering applications.
Author(s)/Presenter(s):
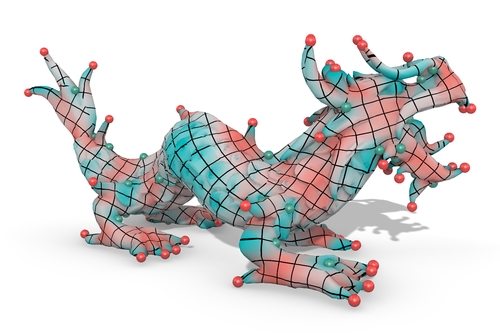
Computing Sparse Cones with Bounded Distortion for Conformal Parameterizations
Abstract: We propose a novel method to generate sparse cone singularities with bounded distortion constraints for conformal parameterizations. It is formulated as minimizing the ℓ0-norm of Gaussian curvature of vertices with hard constraints of bounding the distortion that is measured by the ℓ2-norm of the log conformal factor. We use the reweighted ℓ1-norm to approximate the ℓ0-norm and solve each convex weighted ℓ1 minimization subproblem by the Douglas-Rachford (DR) splitting scheme. To quickly generate sparse cones, we modify DR splitting by weighting the ℓ2-norm of the proximal mapping to force the small Gaussian curvature to quickly approach zero. Accordingly, compared with the conventional DR splitting, the modified method performs one to two orders of magnitude faster. Besides, we perform variable substitution of log conformal factors to simplify the computation process for acceleration. Our algorithm is able to bound distortion to compute sparse cone singularities, so that the resulting conformal parameterizations achieve a favorable tradeoff between the area distortion and the cone number. We demonstrate its effectiveness and feasibility on a large number of models.
Author(s)/Presenter(s):
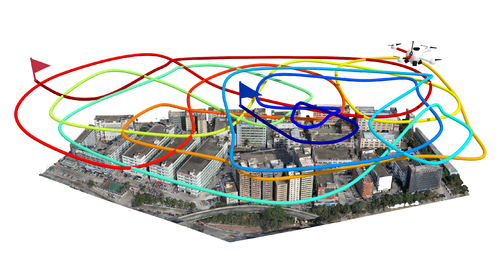
Continuous Aerial Path Planning for 3D Urban Scene Reconstruction
Abstract: We introduce the first path-oriented drone trajectory planning algorithm, which performs continuous (i.e., dense) image acquisition along an aerial path and explicitly factors path quality into an optimization along with scene reconstruction quality. Specifically, our method takes as input a rough 3D scene proxy and produces a drone trajectory and image capturing setup, which efficiently yields a high-quality reconstruction of the 3D scene based on three optimization objectives: one to maximize the amount of 3D scene information that can be acquired along the entirety of the trajectory, another to optimize the scene capturing efficiency by maximizing the scene information that can be acquired per unit length along the aerial path, and the last one to minimize the total turning angles along the aerial path, so as to reduce the number of sharp turns. Our search scheme is based on the rapidly-exploring random tree framework, resulting in a final trajectory as a single path through the search tree. Unlike state-of-the-art works, our joint optimization for view selection and path planning is performed in a single step. We comprehensively evaluate our method not only on benchmark virtual datasets as in existing works but also on several large-scale real urban scenes. We demonstrate that the continuous paths optimized by our method can effectively reduce onsite acquisition cost using drones, while achieving high-fidelity 3D reconstruction, compared to existing planning methods and oblique photography, a mature and popular industry solution.
Author(s)/Presenter(s):
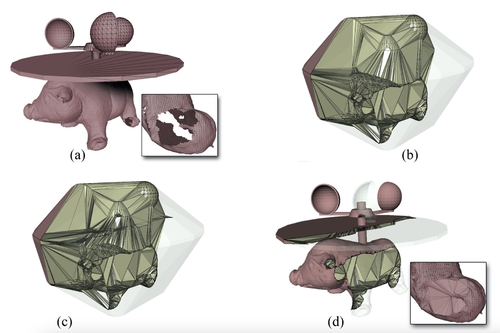
Convex polyhedral meshing for robust solid modeling
Abstract: We introduce a new technique to create a mesh of convex polyhedra representing the interior volume of a triangulated input surface. Our approach is particularly tolerant to defects in the input, which is allowed to self-intersect, to be non-manifold, disconnected, and to contain surface holes and gaps. We guarantee that the input surface is exactly represented as the union of polygonal facets of the output volume mesh. Thanks to our algorithm, traditionally difficult solid modeling operations such as mesh booleans and Minkowski sums become surprisingly robust and easy to implement, even if the input has defects. Our technique leverages on the recent concept of indirect geometric predicate to provide an unprecedented combination of guaranteed robustness and speed, thus enabling the practical implementation of robust though flexible solid modeling systems. We have extensively tested our method on all the 10000 models of the Thingi10k dataset, and concluded that no existing method provides comparable robustness, precision and performances.
Author(s)/Presenter(s):
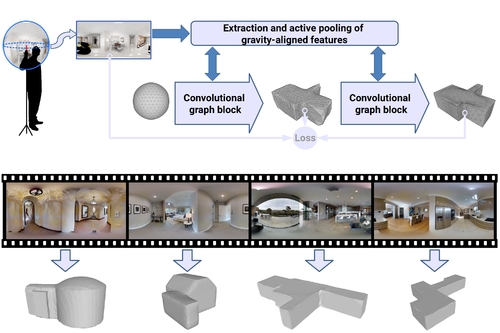
Deep3DLayout: 3D Reconstruction of an Indoor Layout from a Spherical Panoramic Image
Abstract: Recovering the 3D shape of the bounding permanent surfaces of a room from a single image is a key component of indoor reconstruction pipelines. In this article, we introduce a novel deep learning technique capable to produce, at interactive rates, a tessellated bounding 3D surface from a single $360^\circ$ image. Differently from prior solutions, we fully address the problem in 3D, significantly expanding the reconstruction space of prior solutions. A graph convolutional network directly infers the room structure as a 3D mesh by progressively deforming a graph-encoded tessellated sphere mapped to the spherical panorama, leveraging perceptual features extracted from the input image. Important 3D properties of indoor environments are exploited in our design. In particular, gravity-aligned features are actively incorporated in the graph in a projection layer that exploits the recent concept of multi head self-attention, and specialized losses guide towards plausible solutions even in presence of massive clutter and occlusions. Extensive experiments demonstrate that our approach outperforms current state of the art methods in terms of accuracy and capability to reconstruct more complex environments.
Author(s)/Presenter(s):
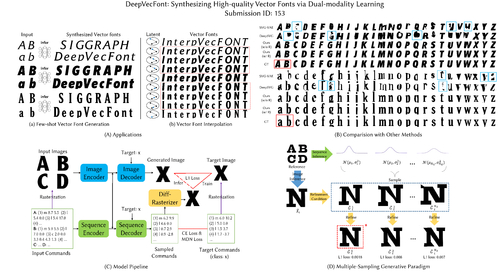
DeepVecFont: Synthesizing High-quality Vector Fonts via Dual-modality Learning
Abstract: Automatic font generation based on deep learning has aroused a lot of interest in the last decade. However, only a few recently-reported approaches are capable of directly generating vector glyphs and their results are still far from satisfactory. In this paper, we propose a novel method, DeepVecFont, to effectively resolve this problem. Using our method, for the first time, visually-pleasing vector glyphs whose quality and compactness are both comparable to human-designed ones can be automatically generated. The key idea of our DeepVecFont is to adopt the techniques of image synthesis, sequence modeling and differentiable rasterization to exhaustively exploit the dual-modality information (i.e., raster images and vector outlines) of vector fonts. The highlights of this paper are threefold. First, we design a dual-modality learning strategy which utilizes both image-aspect and sequence-aspect features of fonts to synthesize vector glyphs. Second, we provide a new generative paradigm to handle unstructured data (e.g., vector glyphs) by randomly sampling plausible synthesis results to get the optimal one which is further refined under the guidance of generated structured data (e.g., glyph images). Finally, qualitative and quantitative experiments conducted on a publicly-available dataset demonstrate that our method obtains high-quality synthesis results in the applications of vector font generation and interpolation, significantly outperforming the state of the art.
Author(s)/Presenter(s):
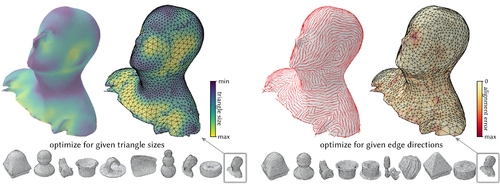
Differentiable Surface Triangulation
Abstract: Triangle meshes remain the most popular data representation for surface geometry. This ubiquitous representation is essentially a hybrid one that decouples continuous vertex locations from the discrete topological triangulation. Unfortunately, the combinatorial nature of the triangulation prevents taking derivatives over the space of possible meshings of any given surface. As a result, to date, mesh processing and optimization techniques have been unable to truly take advantage of modular gradient descent components of modern optimization frameworks. In this work, we present a differentiable surface triangulation that enables optimization for any per-vertex or per-face differentiable objective function over the space of underlying surface triangulations. Our method builds on the result that any 2D triangulation can be achieved by a suitably perturbed weighted Delaunay triangulation. We translate this result into a computational algorithm by proposing a soft relaxation of the classical weighted Delaunay triangulation and optimizing over vertex weights and vertex locations. We extend the algorithm to 3D by decomposing shapes into developable sets and differentiably meshing each set with suitable boundary constraints. We demonstrate the efficacy of our method on various planar and surface meshes on a range of difficult-to-optimize objective functions.
Author(s)/Presenter(s):
Differentiable Time-Gated Rendering
Abstract: The continued advancements of time-of-flight imaging devices have enabled new imaging pipelines with numerous applications. Consequently, several forward rendering techniques capable of accurately and efficiently simulating these devices have been introduced. However, general-purpose differentiable rendering techniques that estimate derivatives of time-of-flight images are still lacking. In this paper, we introduce a new theory of differentiable time-gated rendering that enjoys the generality of differentiating with respect to arbitrary scene parameters. Our theory also allows the design of advanced Monte Carlo estimators capable of handling cameras with near-delta or discontinuous time gates. We validate our theory by comparing derivatives generated with our technique and finite differences. Further, we demonstrate the usefulness of our technique using a few proof-of-concept inverse-rendering examples that simulate several time-of-flight imaging scenarios.
Author(s)/Presenter(s):
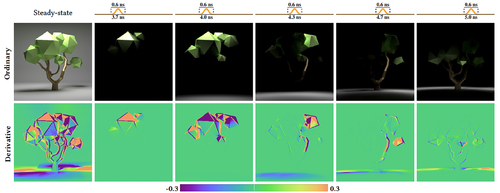
Differentiable Transient Rendering
Abstract: Recent differentiable rendering techniques have become key tools to tackle many inverse problems in graphics and vision. Existing models, however, assume steady-state light transport, i.e., infinite speed of light. While this is a safe assumption for many applications, recent advances in ultrafast imaging leverage the wealth of information that can be extracted from the exact time of flight of light. In this context, physically-based transient rendering allows to efficiently simulate and analyze light transport considering that the speed of light is indeed finite. In this paper, we introduce a novel differentiable transient rendering framework, to help bring the potential of differentiable approaches into the transient regime. To differentiate the transient path integral we need to take into account that scattering events at path vertices are no longer independent; instead, tracking the time of flight of light requires treating such scattering events at path vertices jointly as a multidimensional, evolving manifold. We thus turn to the generalized transport theorem, and introduce a novel correlated importance term, which links the time-integrated contribution of a path to its light throughput, and allows us to handle discontinuities in the light and sensor functions. Last, we present results in several challenging scenarios where the time of flight of light plays an important role such as optimizing indices of refraction, non-line-of-sight tracking with nonplanar relay walls, and non-line-of-sight tracking around two corners.
Author(s)/Presenter(s):

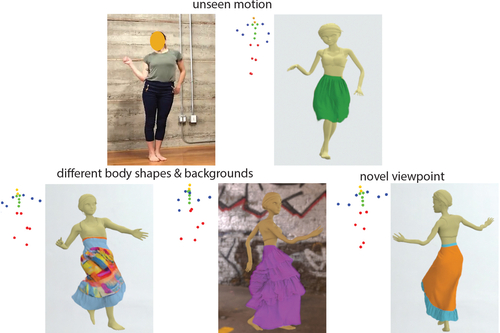
Dynamic Neural Garments
Abstract: A vital task of the wider digital human effort is the creation of realistic garments on digital avatars, both in the form of characteristic fold patterns and wrinkles in static frames as well as richness of garment dynamics under avatars' motion. Existing workflow of modeling, simulation, and rendering closely replicates the physics behind real garments, but is tedious and requires repeating most of the workflow under changes to characters' motion, camera angle, or garment resizing. Although data-driven solutions exist, they either focus on static scenarios or only handle dynamics of tight garments. We present a solution that, at test time, takes in body joint motion to directly produce realistic dynamic garment image sequences. Specifically, given the target joint motion sequence of an avatar, we propose dynamic neural garments to synthesize plausible dynamic garment appearance from a desired viewpoint. Technically, our solution generates a coarse garment proxy sequence, learns deep dynamic features attached to this template, and neurally renders the features to produce appearance changes such as folds, wrinkles, and silhouettes. We demonstrate generalization behavior to both unseen motion and unseen camera views. Further, our network can be fine-tuned to adopt to new body shape and/or background images. We demonstrate our method on a wide range of real and synthetic garments. We also provide comparisons against existing neural rendering and image sequence translation approaches, and report clear quantitative and qualitative improvements.
Author(s)/Presenter(s):
Efficient and Robust Discrete Conformal Equivalence with Boundary
Abstract: We describe an efficient algorithm to compute a discrete metric with prescribed Gaussian curvature at all interior vertices and prescribed geodesic curvature along the boundary of a mesh. The metric is (discretely) conformally equivalent to the input metric. Its construction is based on theory developed in [Gu et al. 2018] and [Springborn 2020], relying on results on hyperbolic ideal Delaunay triangulations. Generality is achieved by considering the surface’s intrinsic triangulation as a degree of freedom, and particular attention is paid to the proper treatment of surface boundaries. While via a double cover approach the case with boundary can be reduced to the case without boundary quite naturally, the implied symmetry of the setting causes additional challenges related to stable Delaunay-critical configurations that we address explicitly. We furthermore explore the numerical limits of the approach and derive continuous maps from the discrete metrics.
Author(s)/Presenter(s):

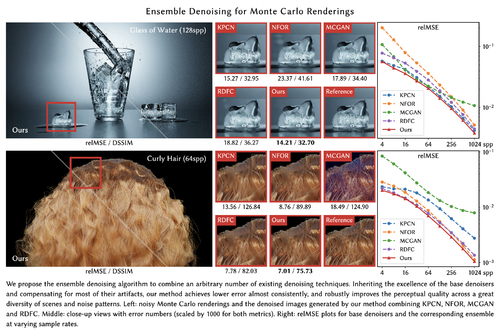
Ensemble Denoising for Monte Carlo Renderings
Abstract: Various denoising methods have been proposed to clean up the noise in Monte Carlo (MC) renderings, each having different advantages, disadvantages, and applicable scenarios. In this paper, we present Ensemble Denoising, an optimization-based technique that combines multiple individual MC denoisers. The combined image is modeled as a per-pixel weighted sum of output images from the individual denoisers. Computation of the optimal weights is formulated as a constrained quadratic programming problem, where we apply a dual-buffer strategy to estimate the overall MSE. We further propose an iterative solver to overcome practical issues involved in the optimization. Besides nice theoretical properties, our ensemble denoiser is demonstrated to be effective and robust and outperforms any individual denoiser across dozens of scenes and different levels of sample rates. We also perform a comprehensive analysis on the selection of individual denoisers to be combined, providing important and practical guides for users.
Author(s)/Presenter(s):
ExtraNet: Real-time Extrapolated Rendering for Low-latency Temporal Supersampling
Abstract: Both the frame rate and the latency are crucial to the performance of real-time rendering applications such as video games. Spatial supersampling methods, such as the Deep Learning SuperSampling (DLSS), have been proven successful at decreasing the rendering time of each frame by rendering at a lower resolution. But temporal supersampling methods that directly aim at producing more frames on the fly are still not practically available. This is mainly due to both its own computational cost and the latency introduced by interpolating frames from the future. In this paper, we present ExtraNet, an efficient neural network that predicts accurate shading results on an extrapolated frame, to minimize both the performance overhead and the latency. With the help of the rendered auxiliary geometry buffers of the extrapolated frame, and the temporally reliable motion vectors, we train our ExtraNet to perform two tasks simultaneously: irradiance in-painting for regions that cannot find historical correspondences, and accurate ghosting-free shading prediction for regions where temporal information is available. We present a robust hole-marking strategy to automate the classification of these tasks, as well as the data generation from a series of high-quality production-ready scenes. Finally, we use lightweight gated convolutions to enable fast inference. As a result, our ExtraNet is able to produce plausibly extrapolated frames without easily noticeable artifacts, delivering a 1.5x to near 2x increase in frame rates with minimized latency in practice.
Author(s)/Presenter(s):

EyelashNet: A Dataset and A Baseline Method for Eyelash Matting
Abstract: Eyelashes play a crucial part in the human facial structure and largely affect the facial attractiveness in modern cosmetic design. However, the appearance and structure of eyelashes can easily induce severe artifacts in high-fidelity multi-view 3D face reconstruction. Unfortunately it is highly challenging to remove eyelashes from portrait images using both traditional and learning-based matting methods due to the delicate nature of eyelashes and the lack of eyelash matting dataset. To this end, we present EyelashNet, the first eyelash matting dataset which contains 5,400 high-quality eyelash matting data captured from real world and 5,272 virtual eyelash matting data created by rendering avatars. Our work consists of a capture stage and an inference stage to automatically capture and annotate eyelashes instead of tedious manual efforts. The capture is based on a specifically-designed fluorescent labeling system. By coloring the eyelashes with a safe and invisible fluorescent substance, our system takes paired photos with colored and normal eyelashes by turning the equipped ultraviolet (UVA) flash on and off. We further correct the alignment between each pair of photos and use a novel alpha matte inference network to extract the eyelash alpha matte. As there is no prior eyelash dataset, we propose a progressive training strategy that progressively fuses captured eyelash data with virtual eyelash data to learn the latent semantics of real eyelashes. As a result, our method can accurately extract eyelash alpha mattes from fuzzy and self-shadow regions such as pupils, which is almost impossible by manual annotations. To validate the advantage of EyelashNet, we present a baseline method based on deep learning that achieves state-of-the-art eyelash matting performance with RGB portrait images as input. We also demonstrate that our work can largely benefit important real applications including high-fidelity personalized avatar and cosmetic design.
Author(s)/Presenter(s):

Fast Volume Rendering with Spatiotemporal Reservoir Resampling
Abstract: Volume rendering under complex, dynamic lighting is challenging, especially if targeting real-time. To address this challenge, we extend a recent direct illumination sampling technique, spatiotemporal reservoir resampling, to multi-dimensional path space for volumetric media. By fully evaluating just a single path sample per pixel, our volumetric path tracer shows unprecedented convergence. To achieve this, we properly estimate the chosen sample’s probability via approximate perfect importance sampling with spatiotemporal resampling. A key observation is recognizing that applying cheaper, biased techniques to approximate scattering along candidate paths (during resampling) does not add bias when shading. This allows us to combine transmittance evaluation techniques: cheap approximations where evaluations must occur many times for reuse, and unbiased methods for final, per-pixel evaluation. With this reformulation, we achieve low-noise, interactive volumetric path tracing with arbitrary dynamic lighting, including volumetric emission, and maintain interactive performance even on high-resolution volumes. When paired with denoising, our low-noise sampling helps preserve smaller scale volumetric details.
Author(s)/Presenter(s):

Fast and Accurate Spherical Harmonics Products
Abstract: Spherical Harmonics (SH) have been proven as a powerful tool for rendering, especially in real-time applications within the Precomputed Radiance Transfer (PRT) system. Spherical harmonics possess nice properties such as the orthogonality. However, computations of triple products and multiple products operations are often the bottlenecks that prevent moderately high-frequency use of spherical harmonics. Specifically, the previous method for accurate SH triple products of order $n$ has a time complexity of $O(n^5)$, which is a heavy burden for most real-time applications. Even worse, a brute-force way to compute $k$-multiple products would take $O(n^{2k})$ time. In this paper, we propose a fast and accurate method for spherical harmonics triple products with the time complexity of only $O(n^3)$, and easily extensible to $k$-multiple products with the time complexity of $O(kn^3+k^2n^2\log(kn))$. Our key insight is to conduct the triple and multiple products in the Fourier space, in which the multiplications can be performed much more efficiently. To our knowledge, our method is theoretically the fastest for accurate spherical harmonics triple and multiple products. And in practice, we demonstrate the efficiency of our method in mid-frequency relighting and occlusion shadow fields applications.
Author(s)/Presenter(s):

Fast and Versatile Fluid-Solid Coupling for Turbulent Flow Simulation
Abstract: The intricate motions and complex vortical structures generated by the interaction between fluids and solids are visually fascinating. However, reproducing such a two-way coupling between thin objects and turbulent fluids numerically is notoriously challenging and computationally costly: existing approaches such as cut-cell or immersed-boundary methods have difficulty achieving physical accuracy, or even visual plausibility, of simulations involving fast-evolving flows with immersed objects of arbitrary shapes. In this paper, we propose an efficient and versatile approach for simulating two-way fluid-solid coupling within the kinetic (lattice-Boltzmann) fluid simulation framework, valid for both laminar and highly turbulent flows, and for both thick and thin objects. We introduce a novel hybrid approach to fluid-solid coupling which systematically involves a mesoscopic double-sided bounce-back scheme followed by a cut-cell velocity correction for a more robust and plausible treatment of turbulent flows near moving (thin) solids, preventing flow penetration and reducing boundary artifacts significantly. Coupled with an efficient approximation to simplify geometric computations, the whole boundary treatment method preserves the inherent massively parallel computational nature of the kinetic method. Moreover, we propose simple GPU optimizations of the core LBM algorithm which achieve an even higher computational efficiency than the state-of-the-art kinetic fluid solvers in graphics. We demonstrate the accuracy and efficacy of our two-way coupling through various challenging simulations involving a variety of rigid body solids and fluids at both high and low Reynolds numbers. Finally, comparisons to existing methods on benchmark data and real experiments further highlight the superiority of our method.
Author(s)/Presenter(s):

Foids: Bio-Inspired Fish Simulation for Generating Synthetic Datasets
Abstract: We present a bio-inspired fish simulation platform, which we call "Foids", to generate realistic synthetic datasets for an use in computer vision algorithm training. This is a first-of-its-kind synthetic dataset platform for fish, which generates all the 3D scenes just with a simulation. One of the major challenges in deep learning based computer vision is the preparation of the annotated dataset. It is already hard to collect a good quality video dataset with enough variations; moreover, it is a painful process to annotate a sufficiently large video dataset frame by frame. This is especially true when it comes to a fish dataset because it is difficult to set up a camera underwater and the number of fish (target objects) in the scene can range up to 30,000 in a fish cage on a fish farm. All of these fish need to be annotated with labels such as a bounding box or silhouette, which can take hours to complete manually, even for only a few minutes of video. We solve this challenge by introducing a realistic synthetic dataset generation platform that incorporates details of biology and ecology studied in the aquaculture field. Because it is a simulated scene, it is easy to generate the scene data with annotation labels from the 3D mesh geometry data and transformation matrix. To this end, we develop an automated fish counting system utilizing the part of synthetic dataset that shows comparable counting accuracy to human eyes, which reduces the time compared to the manual process, and reduces physical injuries sustained by the fish.
Author(s)/Presenter(s):

FreeStyleGAN: Free-view Editable Portrait Rendering with the Camera Manifold
Abstract: Current Generative Adversarial Networks (GANs) produce photorealistic renderings of portrait images. Embedding real images into the latent space of such models enables high-level image editing. While recent methods provide considerable semantic control over the (re-)generated images, they can only generate a limited set of viewpoints and cannot explicitly control the camera. Such 3D camera control is required for 3D virtual and mixed reality applications. In our solution, we use a few images of a face to perform 3D reconstruction, and we introduce the notion of the GAN camera manifold, the key element allowing us to precisely define the range of images that the GAN can reproduce in a stable manner. We train a small face-specific neural implicit representation network to map a captured face to this manifold and complement it with a warping scheme to obtain free-viewpoint novel-view synthesis. We show how our approach - due to its precise camera control - enables the integration of a pre-trained StyleGAN into standard 3D rendering pipelines, allowing e.g., stereo rendering or consistent insertion of faces in synthetic 3D environments. Our solution proposes the first truly free-viewpoint rendering of realistic faces at interactive rates, using only a small number of casual photos as input, while simultaneously allowing semantic editing capabilities, such as facial expression or lighting changes.
Author(s)/Presenter(s):

FrictionalMonolith: A Monolithic Optimization-based Approach for Granular Flow with Contact-Aware Rigid-Body Coupling
Abstract: We propose FrictionalMonolith, a monolithic pressure-friction-contact solver for more accurately, robustly, and efficiently simulating two-way interactions of rigid bodies with continuum granular materials or inviscid liquids. By carefully formulating the components of such systems within a single unified minimization problem, our solver can simultaneously handle unilateral incompressibility and implicit integration of friction for the interior of the continuum, frictional contact resolution among the rigid bodies, and mutual force exchanges between the continuum and rigid bodies. Our monolithic approach eliminates various problematic artifacts in existing weakly coupled approaches, including loss of volume in the continuum material, artificial drift and slip of the continuum at solid boundaries, interpenetrations of rigid bodies, and simulation instabilities. To efficiently handle this challenging monolithic minimization problem, we present a customized solver for the resulting quadratically constrained quadratic program that combines elements of staggered projections, augmented Lagrangian methods, inexact projected Newton, and active-set methods. We demonstrate the critical importance of a unified treatment and the effectiveness of our proposed solver in a range of practical scenarios.
Author(s)/Presenter(s):

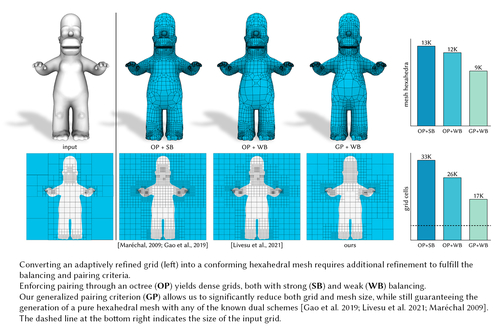
Generalized Adaptive Refinement for Grid-based Hexahedral Meshing
Abstract: Due to their nice numerical properties, conforming hexahedral meshes are considered a prominent computational domain for simulation tasks. However, the automatic decomposition of a general 3D volume into a small number of hexahedral elements is very challenging. Methods that create an adaptive Cartesian grid and convert it into a conforming mesh offer superior robustness and are the only ones concretely used in the industry. Topological schemes that permit this conversion can be applied only if precise compatibility conditions among grid elements are observed. Some of these conditions are local, hence easy to formulate; others are not and are much harder to satisfy. State-of-the-art approaches fulfill these conditions by prescribing additional refinement based on special building rules for octrees. These methods operate in a restricted space of solutions and are prone to severely over-refine the input grids, creating a bottleneck in the simulation pipeline. In this article, we introduce a novel approach to transform a general adaptive grid into a new grid meeting hexmeshing criteria, without resorting to tree rules. Our key insight is that we can formulate all compatibility conditions as linear constraints in an integer programming problem by choosing the proper set of unknowns. Since we operate in a broader solution space, we are able to meet topological hexmeshing criteria at a much coarser scale than methods using octrees, also supporting generalized grids of any shape or topology. We demonstrate the superiority of our approach for both traditional grid-based hexmeshing and adaptive polycube-based hexmeshing. In all our experiments, our method never prescribed more refinement than the prior art, and, in the average case, it introduced close to half the number of extra cells.
Author(s)/Presenter(s):
Generalized Deployable Elastic Geodesic Grids
Abstract: Given a designer created free-form surface in 3d space, our method computes a grid composed of elastic elements which are completely planar and straight. Only by fixing the ends of the planar elements to appropriate locations, the 2d grid bends and approximates the given 3d surface. Our method is based purely on the notions from differential geometry of curves and surfaces and avoids any physical simulations. In particular, we introduce a well-defined elastic grid energy functional that allows identifying networks of curves that minimize the bending energy and at the same time nestle to the provided input surface well. Further, we generalize the concept of such grids to cases where the boundary of the surface does not need to be convex, which allows for the creation of sophisticated and visually pleasing shapes. The algorithm finally ensures that the 2d grid is perfectly planar, making the resulting gridshells inexpensive, easy to fabricate, transport, assemble, and finally also to deploy. Additionally, since the whole structure is pre-strained, it also comes with load-bearing capabilities. We evaluate our method using physical simulation and we also provide a full fabrication pipeline for desktop-size models and present multiple examples of surfaces with elliptic and hyperbolic curvature regions. Our method is meant as a tool for quick prototyping for designers, architects, and engineers since it is very fast and results can be obtained in a matter of seconds.
Author(s)/Presenter(s):

Generalized Fluid Carving With Fast Lattice-Guided Seam Computation
Abstract: In this paper, we introduce a novel method for intelligently resizing a wide range of volumetric data including fluids. Fluid carving, the technique we build upon, only supported particle-based liquid data, and because it was based on image-based techniques, it was constrained to rectangular boundaries. We address these limitations to allow a much more versatile method for volumetric post-processing. By enclosing a region of interest in our lattice structure, users can retarget regions of a volume with non-rectangular boundaries and non-axis-aligned motion. Our approach generalizes to images, videos, liquids, meshes, and even previously unexplored domains such as fire and smoke. We also present a seam computation method that is significantly faster than the previous approach while maintaining the same level of quality, thus making our method more viable for production settings where post-processing workflows are vital.
Author(s)/Presenter(s):
Generative Modelling of BRDF Textures from Flash Images
Abstract: We learn a latent space for easy capture, consistent interpolation, and efficient reproduction of visual material appearance. When users provide a photo of a stationary natural material captured under flashlight illumination, first it is converted into a latent material code. Then, in the second step, conditioned on the material code, our method produces an infinite and diverse spatial field of BRDF model parameters (diffuse albedo, normals, roughness, specular albedo) that subsequently allows rendering in complex scenes and illuminations, matching the appearance of the input picture. Technically, we jointly embed all flash images into a latent space using a convolutional encoder, and -- conditioned on these latent codes -- convert random spatial fields into fields of BRDF parameters using a convolutional neural network (CNN). We condition these BRDF parameters to match the visual characteristics (statistics and spectra of visual features) of the input under matching light. A user study compares our approach favorably to previous work, even those with access to BRDF supervision.
Author(s)/Presenter(s):

Human Dynamics from Monocular Video with Dynamic Camera Movements
Abstract: We propose a new method that reconstructs 3D human motion from in-the-wild video by making full use of prior knowledge on the laws of physics. Previous studies focus on reconstructing joint angles and positions in the body local coordinate frame. Body translations and rotations in the global reference frame are partially reconstructed only when the video has a static camera view. We are interested in overcoming this static view limitation to deal with dynamic view videos. The camera may pan, tilt, and zoom to track the moving subject. Since we do not assume any limitations on camera movements, body translations and rotations from the video do not correspond to absolute positions in the reference frame. The key technical challenge is inferring body translations and rotations from a sequence of 3D full-body poses, assuming the absence of root motion. This inference is possible because human motion obeys the law of physics. Our reconstruction algorithm produces a control policy that simulates 3D human motion imitating the one in the video. Our algorithm is particularly useful for reconstructing highly dynamic movements, such as sports, dance, gymnastics, and parkour actions.
Author(s)/Presenter(s):

HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields
Abstract: Neural Radiance Fields (NeRF) are able to reconstruct scenes with unprecedented fidelity, and various recent works have extended NeRF to handle dynamic scenes. A common approach to reconstruct such non-rigid scenes is through the use of a learned deformation field mapping from coordinates in each input image into a canonical template coordinate space. However, these deformation-based approaches struggle to model changes in topology, as topological changes require a discontinuity in the deformation field, but these deformation fields are necessarily continuous. We address this limitation by lifting NeRFs into a higher dimensional space, and by representing the 5D radiance field corresponding to each individual input image as a slice through this ``hyper-space''. Our method is inspired by level set methods, which model the evolution of surfaces as slices through a higher dimensional surface. We evaluate our method on two tasks: (i) interpolating smoothly between "moments", i.e., configurations of the scene, seen in the input images while maintaining visual plausibility, and (ii) novel-view synthesis at fixed moments. We show that our method, which we dub HyperNeRF, outperforms existing methods on both tasks. Compared to Nerfies, HyperNeRF reduces average error rates by 4.1% for interpolation and 8.6% for novel-view synthesis, as measured by LPIPS.
Author(s)/Presenter(s):

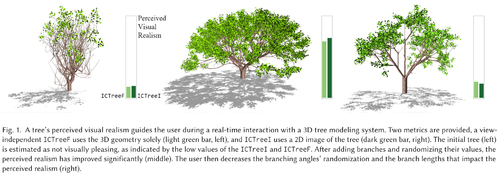
ICTree: Automatic Perceptual Metrics for Tree Models
Abstract: Many algorithms for virtual tree generation exist, but the visual realism of the 3D models is unknown. This problem is usually addressed by performing limited user studies or by a side-by-side visual comparison. We introduce an automated system for realism assessment of the tree model based on their perception. We conducted a user study in which 4,000 participants compared over one million pairs of images to collect subjective perceptual scores of a large dataset of virtual trees. The scores were used to train two neural-network-based predictors. A view independent ICTreeF uses the tree model's geometric features that are easy to extract from any model. The second is ICTreeI that estimates the perceived visual realism of a tree from its image. Moreover, to provide an insight into the problem, we deduce intrinsic attributes and evaluate which features make trees look like real trees. In particular, we show that branching angles, length of branches, and widths are critical for perceived realism. We also provide three datasets: carefully curated 3D tree geometries and tree skeletons with their perceptual scores, multiple views of the tree geometries with their scores, and a large dataset of images with scores suitable for training deep neural networks.
Author(s)/Presenter(s):
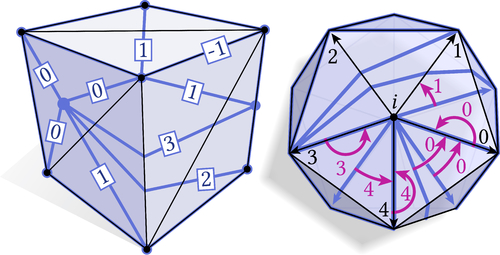
Integer Coordinates for Intrinsic Geometry Processing
Abstract: This paper describes a numerically robust data structure for encoding intrinsic triangulations of polyhedral surfaces. Many applications demand a correspondence between the intrinsic triangulation and the input surface, but existing data structures either rely on floating point values to encode correspondence, or do not support remeshing operations beyond basic edge flips. We instead provide an integer-based data structure that guarantees valid correspondence, even for meshes with near-degenerate elements. Our starting point is the framework of normal coordinates from geometric topology, which we extend to the broader set of operations needed for mesh processing (vertex insertion, edge splits, etc.). The resulting data structure can be used as a drop-in replacement for earlier schemes, automatically improving reliability across a wide variety of applications. As a stress test, we successfully compute an intrinsic Delaunay refinement and associated subdivision for all manifold meshes in the Thingi10k dataset. In turn, we can compute reliable and highly accurate solutions to partial differential equations even on extremely low-quality meshes.
Author(s)/Presenter(s):
Interactive All-Hex Meshing via Cuboid Decomposition
Abstract: Standard PolyCube-based hexahedral (hex) meshing methods aim to deform the input domain into an axis-aligned PolyCube volume with integer corners; if this deformation is bijective, then applying the inverse map to the voxelized PolyCube yields a valid hex mesh. A key challenge in these methods is to maintain the bijectivity of the PolyCube deformation, thus reducing the robustness of these algorithms. In this work, we present an interactive pipeline for hex meshing that sidesteps this challenge by using a new representation of PolyCubes as unions of cuboids. We begin by deforming the input tetrahedral mesh into a near-PolyCube domain whose faces are close but not perfectly aligned to the major axis directions. We then build a PolyCube by optimizing the layout of a set of cuboids with user guidance to closely fit the deformed domain. Finally, we construct an inversion-free pullback map from the voxelized PolyCube to the input domain while optimizing for mesh quality metrics. We allow extensive user control over each stage, such as editing the voxelized PolyCube, positioning surface vertices, and exploring the trade-off among competing quality metrics, while also providing automatic alternatives. We validate our method on over one hundred shapes, including models that are challenging for past PolyCube-based and frame-field-based methods. Our pipeline reliably produces hex meshes with quality on par with or better than state-of-the-art. We additionally conduct a user study with 20 participants in which the majority prefer hex meshes they make using our tool to the ones from automatic state-of-the-art methods. This demonstrates the need for intuitive interactive hex meshing tools where the user can dictate the priorities of their mesh.
Author(s)/Presenter(s):

Interactive Cutting and Tearing in Projective Dynamics with Progressive Cholesky Updates
Abstract: We propose a new algorithm for updating a Cholesky factorization which speeds up Projective Dynamics simulations with topological changes. Our approach addresses an important limitation of the original Projective Dynamics, i.e., that topological changes such as cutting, fracturing, or tearing require full refactorization which compromises computation speed, especially in real-time applications. Our method progressively modifies the Cholesky factor of the system matrix in the global step instead of computing it from scratch. Only a small amount of overhead is added since most of the topological changes in typical simulations are continuous and gradual. Our method is based on the update and downdate routine in CHOLMOD but, unlike recent related work, supports dynamic sizes of the system matrix and the addition of new vertices. Our approach allows us to introduce clean cuts and perform interactive remeshing. Our experiments show that our method works particularly well in simulation scenarios involving cutting, tearing, and local remeshing operations.
Author(s)/Presenter(s):

Intuitive and Efficient Roof Modeling for Reconstruction and Synthesis
Abstract: We propose a novel and flexible roof modeling approach that can be used for constructing planar 3D polygon roof meshes. Our method uses a graph structure to encode roof topology and enforces the roof validity by optimizing a simple but effective planarity metric we propose. This approach is significantly more efficient than using general purpose 3D modeling tools such as 3ds Max or SketchUp, and more powerful and expressive than specialized tools such as the straight skeleton. Our optimization-based formulation is also flexible and can accommodate different styles and user preferences for roof modeling. We showcase two applications. The first application is an interactive roof editing framework that can be used for roof design or roof reconstruction from aerial images. We highlight the efficiency and generality of our approach by constructing a mesh-image paired dataset consisting of 2539 roofs. Our second application is a generative model to synthesize new roof meshes from scratch. We propose to combine machine learning and our roof optimization techniques, by using transformers and graph convolutional networks to model roof topology, and our roof optimization methods to enforce the planarity constraint.
Author(s)/Presenter(s):
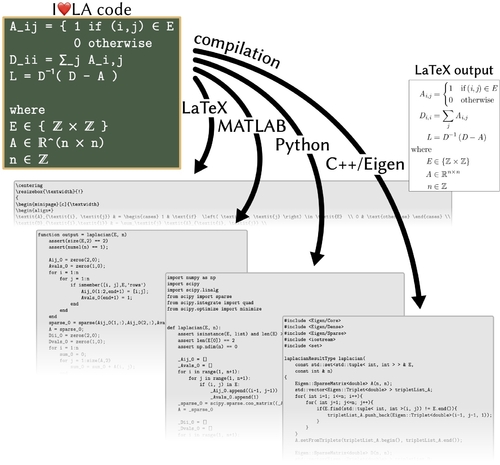
I❤️LA: Compilable Markdown for Linear Algebra
Abstract: Communicating linear algebra in written form is challenging: mathematicians must choose between writing in languages that produce well-formatted but semantically-underdefined representations such as LaTeX; or languages with well-defined semantics but notation unlike conventional math, such as C++/Eigen. In both cases, the underlying linear algebra is obfuscated by the requirements of esoteric language syntax (as in LaTeX) or awkward APIs due to language semantics (as in C++). The gap between representations results in communication challenges, including underspecified and irreproducible research results, difficulty teaching math concepts underlying complex numerical code, as well as repeated, redundant, and error-prone translations from communicated linear algebra to executable code. We introduce I❤️LA, a language with syntax designed to closely mimic conventionally-written linear algebra, while still ensuring an unambiguous, compilable interpretation. Inspired by Markdown, a language for writing naturally-structured plain text files that translate into valid HTML, I❤️LA allows users to write linear algebra in text form and compile the same source into LaTeX, C++/Eigen, Python/NumPy/SciPy, and MATLAB, with easy extension to further math programming environments. We outline the principles of our language design and highlight design decisions that balance between readability and precise semantics, and demonstrate through case studies the ability for I❤️LA to bridge the semantic gap between conventionally-written linear algebra and unambiguous interpretation in math programming environments.
Author(s)/Presenter(s):
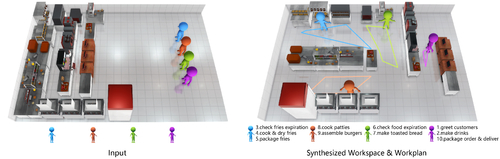
Joint Computational Design of Workspaces and Workplans
Abstract: Humans assume different production roles in a workspace. On one hand, humans design workplans to complete tasks as efficiently as possible in order to improve productivity. On the other hand, a nice workspace is essential to facilitate teamwork. In this way, workspace design and workplan design complement each other. Inspired by such observations, we propose an automatic approach to jointly design a workspace and a workplan. Taking staff properties, a space, and work equipment as input, our approach jointly optimizes a workspace and a workplan, considering performance factors such as time efficiency and congestion avoidance, as well as workload factors such as walk effort, turn effort, and workload balances. To enable exploration of design trade-offs, our approach generates a set of Pareto-optimal design solutions with strengths on different objectives, which can be adopted for different work scenarios. We apply our approach to synthesize workspaces and workplans for different workplaces such as a fast food kitchen and a supermarket. We also extend our approach to incorporate other common work considerations such as dynamic work demands and accommodating staff members with different physical capabilities. Evaluation experiments with simulations validate the efficacy of our approach for synthesizing effective workspaces and workplans.
Author(s)/Presenter(s):
Kaleidoscopic Structured Light
Abstract: Full surround 3D imaging for shape acquisition is essential for generating digital replicas of real-world objects. Surrounding an object we seek to scan with a kaleidoscope, that is, a configuration of multiple planar mirrors, produces an image of the object that encodes information from a combinatorially large number of virtual viewpoints. This information is practically useful for the full surround 3D reconstruction of the object, but cannot be used directly, as we do not know what virtual viewpoint each image pixel corresponds---the pixel label. We introduce a structured light system that combines a projector and a camera with a kaleidoscope. We then prove that we can accurately determine the labels of projector and camera pixels, for arbitrary kaleidoscope configurations, using the projector-camera epipolar geometry. We use this result to show that our system can serve as a multi-view structured light system with hundreds of virtual projectors and cameras. This makes our system capable of scanning complex shapes precisely and with full coverage. We demonstrate the advantages of the kaleidoscopic structured light system by scanning objects that exhibit a large range of shapes and reflectances.
Author(s)/Presenter(s):

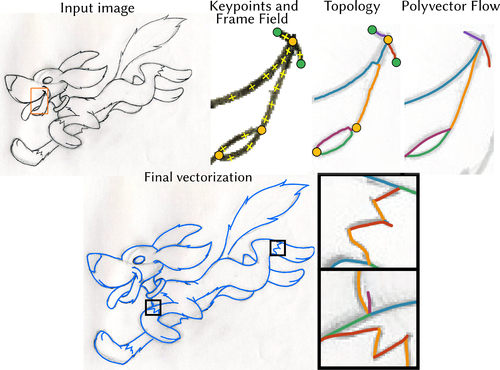
Keypoint-Driven Line Drawing Vectorization via PolyVector Flow
Abstract: Line drawing vectorization is a daily task in graphic design, computer animation, and engineering, necessary to convert raster images to a set of curves for editing and geometry processing. Despite recent progress in the area, automatic vectorization tools often produce spurious branches or incorrect connectivity around curve junctions; or smooth out sharp corners. These issues detract from the use of such vectorization tools, both from an aesthetic viewpoint and for feasibility of downstream applications (e.g., automatic coloring or inbetweening). We address these problems by introducing a novel line drawing vectorization algorithm that splits the task into three components: (1) finding keypoints, i.e., curve endpoints, junctions, and sharp corners; (2) extracting drawing topology, i.e., finding connections between keypoints; and (3) computing the geometry of those connections. We compute the optimal geometry of the connecting curves via a novel geometric flow --- PolyVector flow --- that aligns the curves to the drawing, disambiguating directions around Y-, X-, and T-junctions. We show that our system robustly infers both the geometry and topology of detailed complex drawings. We validate our system both quantitatively and qualitatively, demonstrating that our method visually outperforms previous work.
Author(s)/Presenter(s):
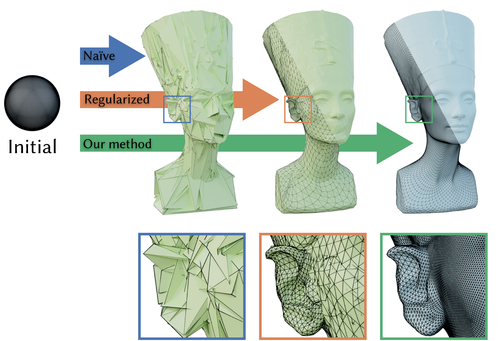
Large Steps in Inverse Rendering of Geometry
Abstract: Inverse reconstruction from images is a central problem in many scientific and engineering disciplines. Recent progress on differentiable rendering has led to methods that can efficiently differentiate the full process of image formation with respect to millions of parameters to solve such problems via gradient-based optimization. At the same time, the availability of cheap derivatives does not necessarily make an inverse problem easy to solve. Mesh-based representations remain a particular source of irritation: an adverse gradient step involving vertex positions could turn parts of the mesh inside-out, introduce numerous local self-intersections, or lead to inadequate usage of the vertex budget due to distortion. These types of issues are often irrecoverable in the sense that subsequent optimization steps will further exacerbate them. In other words, the optimization lacks robustness due to an objective function with substantial non-convexity. Such robustness issues are commonly mitigated by imposing additional regularization, typically in the form of Laplacian energies that quantify and improve the smoothness of the current iterate. However, regularization introduces its own set of problems: solutions must now compromise between solving the problem and being smooth. Furthermore, gradient steps involving a Laplacian energy resemble Jacobi's iterative method for solving linear equations that is known for its exceptionally slow convergence. We propose a simple and practical alternative that casts differentiable rendering into the framework of preconditioned gradient descent. Our preconditioner biases gradient steps towards smooth solutions without requiring the final solution to be smooth. In contrast to Jacobi-style iteration, each gradient step propagates information among all variables, enabling convergence using fewer and larger steps. Our method is not restricted to meshes and can also accelerate the reconstruction of other representations, where smooth solutions are generally expected. We demonstrate its superior performance in the context of geometric optimization and texture reconstruction.
Author(s)/Presenter(s):
Layered Neural Atlases for Consistent Video Editing
Abstract: We present a method that decomposes, or “unwraps”, an input video into a set of layered 2D atlases, each providing a unified representation of the appearance of an object (or background) over the video. For each pixel in the video, our method estimates its corresponding 2D coordinate in each of the atlases, giving us a consistent parameterization of the video, along with an associated alpha (opacity) value. Importantly, we design our atlases to be interpretable and semantic, which facilitates easy and intuitive editing in the atlas domain, with minimal manual work required. Edits applied to a single 2D atlas (or input video frame) are automatically and consistently mapped back to the original video frames, while preserving occlusions, deformation, and other complex scene effects such as shadows and reflections. Our method employs a coordinate-based Multilayer Perceptron (MLP) representation for mappings, atlases, and alphas, which are jointly optimized on a per-video basis, using a combination of video reconstruction and regularization losses. By operating purely in 2D, our method does not require any prior 3D knowledge about scene geometry or camera poses, and can handle complex dynamic real world videos. We demonstrate various video editing applications, including texture mapping, video style transfer, image-to-video texture transfer, and segmentation/labeling propagation, all automatically produced by editing a single 2D atlas image.
Author(s)/Presenter(s):

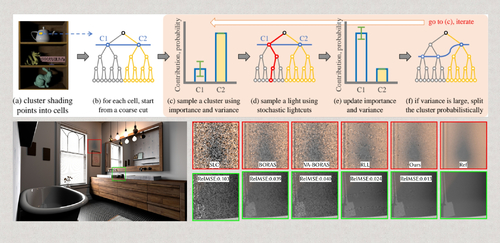
Learning to Cluster for Rendering with Many Lights
Abstract: We present an unbiased online Monte Carlo method for rendering with many lights. Our method adapts both the hierarchical light clustering and the sampling distribution to our collected samples. Designing such a method requires us to make clustering decisions under noisy observation, and making sure that the sampling distribution adapts to our target. Our method is based on two key ideas: a coarse-to-fine clustering scheme that can find good clustering configurations even with noisy samples, and a discrete stochastic successive approximation method that starts from a prior distribution and provably converges to a target distribution. We compare to other state-of-the-art light sampling methods, and show better results both numerically and visually.
Author(s)/Presenter(s):
Learning to Reconstruct Botanical Trees from Single Images
Abstract: We introduce a novel method for reconstructing the 3D geometry of botanical trees from single photographs. Faithfully reconstructing a tree from single-view sensor data is a challenging and open problem because many possible 3D trees exist that fit the tree's shape observed from a single view. We address this challenge by defining a reconstruction pipeline based on three neural networks. The networks simultaneously mask out trees in input photographs, identify a tree's species, and obtain its 3D radial bounding volume -- our novel 3D representation for botanical trees. Radial bounding volumes (RBV) are used to orchestrate a procedural model primed on learned parameters to grow a tree that matches the main branching structure and the overall shape of the captured tree. While the RBV allows us to reconstruct the main branching structure faithfully, we use the procedural model's morphological constraints to generate realistic branching for the tree crown. This constraints the number of solutions of tree models for a given photograph of a tree. We show that our method reconstructs various tree species even when the trees are captured in front of complex backgrounds. Moreover, although our neural networks have been trained on synthetic data with data augmentation, we show that our pipeline performs well for real tree photographs. We evaluate the reconstructed geometries with a number metrics, including leaf area index and maximum radial tree distances.
Author(s)/Presenter(s):

Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation
Abstract: To the best of our knowledge, we first present a live system that generates personalized photorealistic talking-head animation only driven by audio signals at over 30 fps. Our system contains three stages. The first stage is a deep neural network that extracts deep audio features along with a manifold projection to project the features to the target person's speech space. In the second stage, we learn facial dynamics and motions from the projected audio features. The predicted motions include head poses and upper body motions, where the former is generated by an autoregressive probabilistic model which models the head pose distribution of the target person. Upper body motions are deduced from the head poses. In the final stage, we generate conditional feature maps from previous predictions and send them with a candidate image set to an image-to-image translation network to synthesize photorealistic renderings. Our method generalizes well to wild audio and successfully synthesizes high-fidelity personalized facial details, e.g., wrinkles, teeth. Our method also allows explicit control of head poses. Extensive qualitative and quantitative evaluations, along with user studies, demonstrate the superiority of our method over state-of-the-art techniques.
Author(s)/Presenter(s):

Modeling Clothing as a Separate Layer for an Animatable Human Avatar
Abstract: We have recently seen great progress in building photorealistic animatable full-body codec avatars, but generating high-fidelity animation of clothing is still difficult. To address these difficulties, we propose a method to build an animatable clothed body avatar with an explicit representation of the clothing on the upper body from multi-view captured videos. We use a two-layer mesh representation to register each 3D scan separately with the body and clothing templates. In order to improve the photometric correspondence across different frames, texture alignment is then performed through inverse rendering of the clothing geometry and texture predicted by a variational autoencoder. We then train a new two-layer codec avatar with separate modeling of the upper clothing and the inner body layer. To learn the interaction between the body dynamics and clothing states, we use a temporal convolution network to predict the clothing latent code based on a sequence of input skeletal poses. We show photorealistic animation output for three different actors, and demonstrate the advantage of our clothed-body avatars over the single-layer avatars used in previous work. We also show the benefit of an explicit clothing model that allows the clothing texture to be edited in the animation output.
Author(s)/Presenter(s):

Modeling Flower Pigmentation Patterns
Abstract: Although many simulation models of natural phenomena have been developed to date, little attention was given to a major contributor to the beauty of nature: the colorful patterns of flowers. We survey typical patterns and propose methods for simulating them inspired by the current understanding of the biology of floral patterning. The patterns are generated directly on geometric models of flowers, using different combinations of key mathematical models of morphogenesis: vascular patterning, positional information, reaction-diffusion, and random pattern generation. The integration of these models makes it possible to capture a wide range of the flower pigmentation patterns observed in nature.
Author(s)/Presenter(s):

Monte Carlo Denoising via Auxiliary Feature Guided Self-Attention
Abstract: While self-attention has been successfully applied in a variety of natural language processing and computer vision tasks, its application in Monte Carlo (MC) image denoising has not yet been well explored. This paper presents a self-attention based MC denoising deep learning network based on the fact that self-attention is essentially non-local means filtering in the embedding space which makes it inherently very suitable for the denoising task. Particularly, we modify the standard self-attention mechanism to an auxiliary feature guided self-attention that considers the by-products (e.g., auxiliary feature buffers) of the MC rendering process. As a critical prerequisite to fully exploit the performance of self-attention, we design a multi-scale feature extraction stage, which provides a rich set of raw features for the later self-attention module. As self-attention poses a high computational complexity, we describe several ways that accelerate it. Ablation experiments validate the necessity and effectiveness of the above design choices. Comparison experiments show that the proposed self-attention based MC denoising method outperforms the current state-of-the-art methods.
Author(s)/Presenter(s):

Motion Recommendation for Online Character Control
Abstract: Reinforcement learning (RL) has been proven effective in many scenarios, including environment exploration and motion planning. However, its application in data-driven character control has produced relatively simple motion results compared to the recent approaches that use large complex motion data without RL. In this paper, we provide a real-time motion control method that can generate high-quality and complex motion results from various sets of unstructured data while retaining the advantage of using RL, which is the discovery of optimal behaviors by trial and error. We demonstrate the results of a character achieving different tasks, from simple direction control to complex avoidance of moving obstacles. Our system works equally well on biped/quadruped characters, with motion data ranging from 1 to 48 minutes, without any manual intervention. To achieve this, we exploit a finite set of discrete actions where each action represents the full-body future motion features. We first define a subset of actions that can be selected in each state and store these pieces of information in databases during the preprocessing step. The use of this subset of actions enables the effective learning of control policy even from a large motion data. To achieve interactive performance at run-time, we adopt a proposal network and a k-nearest neighbor action sampler.
Author(s)/Presenter(s):

Multi-Class Inverted Stippling
Abstract: We introduce inverted stippling, a method to mimic an inversion technique used by artists when performing stippling. To this end, we extend Linde-Buzo-Gray (LBG) stippling to multi-class LBG (MLBG) stippling with multiple layers. MLBG stippling couples the layers stochastically to optimize for per-layer and global blue-noise properties. We propose a stipple-based filling method to generate solid color backgrounds for inverting areas. Our experiments demonstrate the effectiveness of MLBG; users prefer our inverted stippling results compared to traditional stipple renderings. In addition, we showcase MLBG with color stippling and dynamic multi-class blue-noise sampling, which is possible due to its support for temporal coherence.
Author(s)/Presenter(s):

NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination
Abstract: We address the problem of recovering the shape and spatially-varying reflectance of an object from multi-view images (and their camera poses) of an object illuminated by one unknown lighting condition. This enables the rendering of novel views of the object under arbitrary environment lighting and editing of the object’s material properties. The key to our approach, which we call Neural Radiance Factorization (NeRFactor), is to distill the volumetric geometry of a Neural Radiance Field (NeRF) [Mildenhall et al. 2020] representation of the object into a surface representation and then jointly refine the geometry while solving for the spatially-varying reflectance and environment lighting. Specifically, NeRFactor recovers 3D neural fields of surface normals, light visibility, albedo, and Bidirectional Reflectance Distribution Functions (BRDFs) without any supervision, using only a re-rendering loss, simple smoothness priors, and a data-driven BRDF prior learned from real-world BRDF measurements. By explicitly modeling light visibility, NeRFactor is able to separate shadows from albedo and synthesize realistic soft or hard shadows under arbitrary lighting conditions. NeRFactor is able to recover convincing 3D models for free-viewpoint relighting in this challenging and underconstrained capture setup for both synthetic and real scenes. Qualitative and quantitative experiments show that NeRFactor outperforms classic and deep learning-based state of the art across various tasks. Our videos, code, and data are available at people.csail.mit.edu/xiuming/projects/nerfactor/.
Author(s)/Presenter(s):

Neural 3D Holography: Learning Accurate Wave Propagation Models for 3D Holographic Virtual and Augmented Reality Displays
Abstract: Holographic near-eye displays promise unprecedented capabilities for virtual and augmented reality (VR/AR) systems. The image quality achieved by current holographic displays, however, is limited by the wave propagation models used to simulate the physical optics. We propose a neural-network-parameterized plane-to-multiplane wave propagation model that closes the gap between physics and simulation. Our model is automatically trained using camera feedback and it outperforms related techniques in 2D plane-to-plane settings by a large margin. Moreover, it is the first network-parameterized model to naturally extend to 3D settings, enabling high-quality 3D computer-generated holography using a novel phase regularization strategy of the complex-valued wave field. The efficacy of our approach is demonstrated through extensive experimental evaluation with both VR and optical see-through AR display prototypes.
Author(s)/Presenter(s):
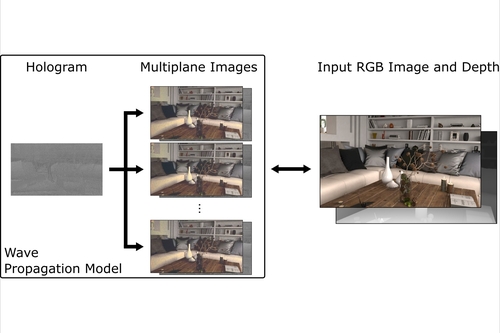
Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control
Abstract: We propose Neural Actor (NA), a new method for high-quality synthesis of humans from arbitrary viewpoints and under arbitrary controllable poses. Our method is developed upon recent neural scene representation and rendering works which learn representations of geometry and appearance from only 2D images. While existing works demonstrated compelling rendering of static scenes and playback of dynamic scenes, photo-realistic reconstruction and rendering of humans with neural implicit methods, in particular under user-controlled novel poses, is still difficult. To address this problem, we utilize a coarse body model as the proxy to unwarp the surrounding 3D space into a canonical pose. A neural radiance field learns pose-dependent geometric deformations and pose- and view-dependent appearance effects in the canonical space from multi-view video input. To synthesize novel views of high fidelity dynamic geometry and appearance, NA leverages 2D texture maps defined on the body model as latent variables for predicting residual deformations and the dynamic appearance. Experiments demonstrate that our method achieves better quality than the state-of-the-arts on playback as well as novel pose synthesis, and can even generalize well to new poses that starkly differ from the training poses. Furthermore, our method also supports shape control on the free-view synthesis of human actors.
Author(s)/Presenter(s):
Neural Frame Interpolation for Rendered Content
Abstract: The demand for creating rendered content continues to drastically grow. As it often is extremely computationally expensive and thus costly to render high-quality computer-generated images, there is a high incentive to reduce this computational burden. Recent advances in learning-based frame interpolation methods have shown exciting progress but still have not achieved the production-level quality which would be required to render fewer pixels and achieve savings in rendering times and costs. Therefore, in this paper we propose a method specifically targeted to achieve high-quality frame interpolation for rendered content. In this setting, we assume that we have full input for every n-th frame in addition to auxiliary feature buffers that are cheap to evaluate (e.g. depth, normals, albedo) for every frame. We propose solutions for leveraging such auxiliary features to obtain better motion estimates, more accurate occlusion handling, and to correctly reconstruct non-linear motion between keyframes. With this, our method is able to significantly push the state-of-the-art in frame interpolation for rendered content and we are able to obtain production-level quality results.
Author(s)/Presenter(s):
Neural Marching Cubes
Abstract: We introduce Neural Marching Cubes (NMC), a data-driven approach for extracting a triangle mesh from a discretized implicit field. Classical MC is defined by coarse tessellation templates isolated to individual cubes. While more refined tessellations have been proposed, they all make heuristic assumptions, such as trilinearity, when determining the vertex positions and local mesh topologies in each cube. In principle, none of these approaches can reconstruct geometric features that reveal coherence or dependencies between nearby cubes (e.g., a sharp edge), as such information is unaccounted for, resulting in poor estimates of the true underlying implicit field. To tackle these challenges, we re-cast MC from a deep learning perspective, by designing tessellation templates more apt at preserving geometric features, and learning the vertex positions and mesh topologies from training meshes, to account for contextual information from nearby cubes. We develop a compact per-cube parameterization to represent the output triangle mesh, while being compatible with neural processing, so that a simple 3D convolutional network can be employed for the training. We show that all topological cases in each cube that are applicable to our design can be easily derived using our representation, and the resulting tessellations can also be obtained naturally and efficiently by following a few design guidelines. In addition, our network learns local features with limited receptive fields, hence it generalizes well to new shapes and new datasets. We evaluate our neural MC approach by quantitative and qualitative comparisons to all well-known MC variants. In particular, we demonstrate the ability of our network to recover sharp features such as edges and corners, a long-standing issue of MC and its variants. Our network also reconstructs local mesh topologies more accurately than previous approaches.
Author(s)/Presenter(s):
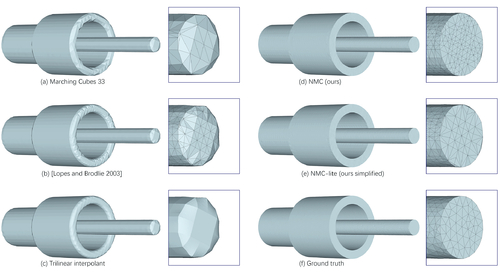
Neural Radiosity
Abstract: We introduce Neural Radiosity, an algorithm to solve the rendering equation by minimizing the norm of its residual similar as in traditional radiosity techniques. Traditional basis functions used in radiosity techniques, such as piecewise polynomials or meshless basis functions are typically limited to representing isotropic scattering from diffuse surfaces. Instead, we propose to leverage Neural Networks to represent the full four-dimensional radiance distribution, and we optimize the Neural Network parameters directly to minimize the norm of the residual. Our approach decouples solving the rendering equation from rendering (perspective) images similar as in traditional radiosity techniques, and allows us to efficiently synthesize arbitrary views of a scene. In addition, we propose a network architecture using geometric learnable features that improves convergence of our solver compared to previous techniques. Our approach leads to an algorithm that is simple to implement and effective on a variety of scenes with non-diffuse surfaces.
Author(s)/Presenter(s):

Optimizing Contact-based Assemblies
Abstract: Modern fabrication methods have greatly simplified manufacturing of complex free-form shapes at an affordable cost, and opened up new possibilities for improving functionality and customization through automatic optimization, shape optimization in particular. However, most existing shape optimization methods focus on single parts. In this work, we focus on supporting shape optimization for assemblies, more specifically, assemblies that are held together by contact and friction. Examples of which include furniture joints, construction set assemblies, certain types of prosthetic devices and many other. To enable this optimization, we present a framework supporting robust and accurate optimization of a number of important functionals, while enforcing constraints essential for assembly functionality: weight, stress, difficulty of putting the assembly together, and how reliably it stays together. Our framework is based on smoothed formulation of elasticity equations with contact, analytically derived shape derivatives, and robust remeshing to enable large changes of shape, and at the same time, maintain accuracy. We demonstrate the improvements it can achieve for a number of computational and experimental examples.
Author(s)/Presenter(s):
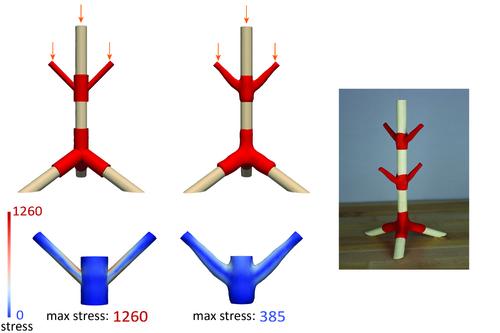
Optimizing Global Injectivity for Constrained Parameterization
Abstract: Injective parameterizations of triangulated meshes are critical across applications but remain challenging to compute. Existing algorithms to find injectivity either require initialization from an injective starting state, which is currently only possible without positional constraints, or else can only prevent triangle inversion, which is insufficient to ensure injectivity. Here we present, to our knowledge, the first algorithm for recovering a globally injective parameterization from an arbitrary non-injective initial mesh subject to stationary constraints. These initial meshes can be inverted, wound about interior vertices and/or overlapping. Our algorithm in turn enables globally injective mapping for meshes with arbitrary positional constraints. Our key contribution is a new energy, called smooth excess area (SEA), that measures non-injectivity in a map. This energy is well-defined across both injective and non-injective maps and is smooth almost everywhere, making it readily minimizable using standard gradient-based solvers starting from a non-injective initial state. Importantly, we show that maps minimizing SEA are guaranteed to be locally injective and almost globally injective, in the sense that the overlapping area can be made arbitrarily small. Analyzing SEA's behavior over a new benchmark set designed to test injective mapping, we find that optimizing SEA successfully recovers globally injective maps for 85% of the benchmark and obtains locally injective maps for 90%. In contrast, state-of-the-art methods for removing triangle inversion obtain locally injective maps for less than 6% of the benchmark, and achieve global injectivity (largely by chance as prior methods are not designed to recover it) on less than 4%.
Author(s)/Presenter(s):
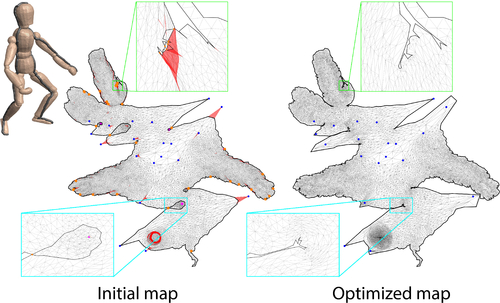
PBNS: Physically Based Neural Simulation for Unsupervised Garment Pose Space Deformation
Abstract: We present a methodology to automatically obtain Pose Space Deformation (PSD) basis for rigged garments through deep learning. Classical approaches rely on Physically Based Simulations (PBS) to animate clothes. These are general solutions that, given a sufficiently fine-grained discretization of space and time, can achieve highly realistic results. However, they are computationally expensive and any scene modification prompts the need of re-simulation. Linear Blend Skinning (LBS) with PSD offers a lightweight alternative to PBS, though, it needs huge volumes of data to learn proper PSD. We propose using deep learning, formulated as an implicit PBS, to unsupervisedly learn realistic cloth Pose Space Deformations in a constrained scenario: dressed humans. Furthermore, we show it is possible to train these models in an amount of time comparable to a PBS of a few sequences. To the best of our knowledge, we are the first to propose a neural simulator for cloth. While deep-based approaches in the domain are becoming a trend, these are data-hungry models. Moreover, authors often propose complex formulations to better learn wrinkles from PBS data. Supervised learning leads to physically inconsistent predictions that require collision solving to be used. Also, dependency on PBS data limits the scalability of these solutions, while their formulation hinders its applicability and compatibility. By proposing an unsupervised methodology to learn PSD for LBS models (3D animation standard), we overcome both of these drawbacks. Results obtained show cloth-consistency in the animated garments and meaningful pose-dependant folds and wrinkles. Our solution is extremely efficient, handles multiple layers of cloth, allows unsupervised outfit resizing and can be easily applied to any custom 3D avatar.
Author(s)/Presenter(s):

Path Graphs: Iterative Path Space Filtering
Abstract: To render higher quality images from the samples generated by path tracing with a very low sample count, we propose a novel path-space filtering approach that processes a fixed collection of paths to refine and improve radiance estimates throughout the scene. Our method operates on a \emph{path graph} consisting of the union of the traced paths with additional neighbor edges inserted between spatially nearby vertices. The approach refines the initial noisy radiance estimates via an aggregation operator, which effectively treats direct and indirect radiance estimates on neighboring path vertices as independent sampling techniques and combines them using well-chosen weights. We also introduce a propagation operator to forward the refined estimates along the paths to successive bounces. We apply the aggregation and propagation operations to the graph iteratively, progressively refining the radiance estimates, converging to fixed-point radiance estimates with lower variance than the original ones. Our approach is lightweight, in the sense that it can be easily plugged into any standard path tracer and neural final image denoiser. Furthermore, it is independent of scene complexity, as the graph size only depends on image resolution and average path depth. We demonstrate that our technique leads to realistic rendering results starting from as low as 1 path per pixel, even in complex indoor scenes dominated by multi-bounce indirect illumination.
Author(s)/Presenter(s):

Perceptual Model for Adaptive Local Shading and Refresh Rate
Abstract: When the rendering budget is limited by power or time, it is necessary to find the combination of rendering parameters, such as resolution and refresh rate, that could deliver the best quality. Variable-rate shading (VRS), introduced in the last generations of GPUs, enables fine control of the rendering quality, in which each 16x16 image tile can be rendered with a different ratio of shader executions. We take advantage of this capability and propose a new method for adaptive control of local shading and refresh rate. The method analyzes texture content, on-screen velocities, luminance, and effective resolution and suggests the refresh rate and a VRS state map that maximizes the quality of animated content under a limited budget. The method is based on the new content-adaptive metric of judder, aliasing, and blur, which is derived from the psychophysical models of contrast sensitivity. To calibrate and validate the metric, we gather data from literature and also collect new measurements of motion quality under variable shading rates, different velocities of motion, texture content, and display capabilities, such as refresh rate, persistence, and angular resolution. The proposed metric and adaptive shading method is implemented as a game engine plugin. Our experimental validation shows a substantial increase in preference of our method over rendering with a fixed resolution and refresh rate, and an existing motion-adaptive technique.
Author(s)/Presenter(s):
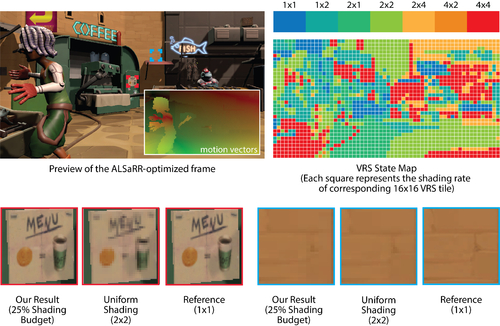
Physical Light-Matter Interaction in Hermite-Gauss Space
Abstract: Our purpose in this paper is two-fold: introduce a computationally-tractable decomposition of the coherence properties of light; and, present a general-purpose light-matter interaction framework for partially-coherent light. In a recent publication, Steinberg and Yan [2021] introduced a framework that generalizes the classical radiometry-based light transport to physical optics. This facilitates a qualitative increase in the scope of optical phenomena that can be rendered, however with the additional expressibility comes greater analytic difficulty: This coherence of light, which is the core quantity of physical light transport, depends initially on the characteristics of the light source, and mutates on interaction with matter and propagation. Furthermore, current tools that aim to quantify the interaction of partially-coherent light with matter remain limited to specific materials and are computationally intensive. To practically represent a wide class of coherence functions, we decompose their modal content in Hermite-Gauss space and derive a set of light-matter interaction formulae, which quantify how matter scatters light and affects its coherence properties. Then, we model matter as a locally-stationary random process, generalizing the prevalent deterministic and stationary stochastic descriptions. This gives rise to a framework that is able to formulate the interaction of arbitrary partially-coherent light with a wide class of matter. Indeed, we will show that our presented formalism unifies a few of the state-of-the-art scatter and diffraction formulae into one cohesive theory. This formulae include the sourcing of partially-coherent light, scatter by rough surfaces and microgeometry, diffraction grating and interference by a layered structure.
Author(s)/Presenter(s):

Physically-based Feature Line Rendering
Abstract: Feature lines visualize the shape and structure of 3D objects, and are an essential component of many non-photorealistic rendering styles. Existing feature line rendering methods, however, are only able to render feature lines in limited contexts, such as on immediately visible surfaces or in specular reflections. We present a novel, path-based method for feature line rendering that allows for the accurate rendering of feature lines in the presence of complex physical phenomena such as glossy reflection, depth-of-field, and dispersion. Our key insight is that feature lines can be modeled as view-dependent light sources. These light sources can be sampled as a part of ordinary paths, and seamlessly integrate into existing physically-based rendering methods. We illustrate the effectiveness of our method in several real-world rendering scenarios with a variety of different physical phenomena.
Author(s)/Presenter(s):

Polarimetric Spatio-Temporal Light Transport Probing
Abstract: Light emitted from a source into a scene can undergo complex interactions with multiple scene surfaces of different material types before being reflected towards a detector. During this transport, every surface reflection and propagation is encoded in the properties of the photons that ultimately reach the detector, including travel time, direction, intensity, wavelength and polarization. Conventional imaging systems capture intensity by integrating over all other dimensions of the incident light into a single quantity, hiding this rich scene information in the accumulated measurements. Existing methods are capable of untangling these measurements into their spatial and temporal dimensions, fueling geometric scene understanding tasks. However, examining polarimetric material properties jointly with geometric properties is an open challenge that could enable unprecedented capabilities beyond geometric scene understanding, allowing to incorporate material-dependent semantics and imaging through complex transport, such as macroscopic scattering. In this work, we close this gap, and propose a computational light-transport imaging method that captures the spatially- and temporally-resolved complete polarimetric response of a scene, which encode rich material properties. Our method hinges on a novel 7D tensor theory of light transport. We discover low-rank structures in the polarimetric tensor dimension and propose a data-driven rotating ellipsometry method that learns to exploit redundancy of the polarimetric structures. We instantiate our theory in two imaging prototypes: spatio-polarimetric imaging and coaxial temporal-polarimetric imaging. This allows us, for the first time, to decompose scene light transport into temporal, spatial, and complete polarimetric dimensions that unveil scene properties hidden to conventional methods. We validate the applicability of our method on diverse tasks, including shape reconstruction with subsurface scattering, seeing through scattering medium, untangling multi-bounce light transport, breaking metamerism with polarization, and spatio-polarimetric decomposition of crystals. The proposed method outperforms conventional methods in all experiments.
Author(s)/Presenter(s):
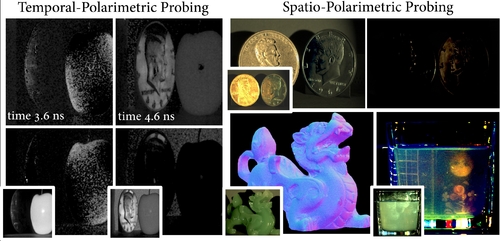
Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
Abstract: We present an algorithm for re-rendering a person from a single image under arbitrary poses. Existing methods often have difficulties in hallucinating occluded contents photo-realistically while preserving the identity and fine details in the source image. We first learn to inpaint the correspondence field between the body surface texture and the source image with a human body symmetry prior. The inpainted correspondence field allows us to transfer/warp local features extracted from the source to the target view even under large pose changes. Directly mapping the warped local features to an RGB image using a simple CNN decoder often leads to visible artifacts. Thus, we extend the StyleGAN generator so that it takes pose as input (for controlling poses) and introduces a spatially varying modulation for the latent space using the warped local features (for controlling appearances). We show that our method compares favorably against the state-of-the-art algorithms in both quantitative evaluation and visual comparison.
Author(s)/Presenter(s):

Practical Pigment Mixing for Digital Painting
Abstract: There is a significant flaw in today's painting software: the colors do not mix like actual paints. E.g., blue and yellow make gray instead of green. This is because the software is built around the RGB representation, which models the mixing of colored lights. Paints, however, get their color from pigments, whose mixing behavior is predicted by the Kubelka-Munk model (K-M). Although it was introduced to computer graphics almost 30 years ago, the K-M model has never been adopted by painting software in practice as it would require giving up the RGB representation, growing the number of per-pixel channels substantially, and depriving the users of painting with arbitrary RGB colors. In this paper, we introduce a practical approach that enables mixing colors with K-M while keeping everything in RGB. We achieve this by establishing a latent color space, where RGB colors are represented as mixtures of primary pigments together with additive residuals. The latents can be manipulated with linear operations, leading to expected, plausible results. We describe the conversion between RGB and our latent representation and show how to implement it efficiently. We prove the viability of our approach on the case of major painting software whose developers integrated our mixing method with minimal effort, making it the first real-world software to provide realistic color mixing in history.
Author(s)/Presenter(s):

Predicting High-Resolution Turbulence Details In Space and Time
Abstract: Predicting intricate details of a turbulent flow field in both space and time from a coarse input remains a major challenge despite the availability of modern machine learning tools. In this paper, we present a simple and effective dictionary-based approach to spatio-temporal upsampling of fluid simulation. We demonstrate that our neural network approach can reproduce the visual complexity of turbulent flows from spatially and temporally coarse velocity fields even when using very few generic training sets. Moreover, since our method generates finer spatial and/or temporal details through embarrassingly-parallel upsampling of small local patches, it can efficiently handle upsampling across a variety of grid resolutions. As a consequence, our method offers a whole range of applications varying from fluid flow upsampling to fluid data compression. We test our method on a series of complex examples, highlighting dramatically better results in spatio-temporal upsampling and flow data compression than existing methods as assessed by both qualitative and quantitative comparisons, demonstrating the efficiency and generalizability of our method for synthesizing turbulent flows.
Author(s)/Presenter(s):

Project Starline: A high-fidelity telepresence system
Abstract: We present a real-time bidirectional communication system that lets two distant users experience a conversation as if they were copresent. It is the first telepresence system that is demonstrably better than 2D videoconferencing, as measured using participant ratings (e.g., presence, attentiveness, reaction-gauging, engagement), meeting recall, and observed nonverbal behaviors (e.g., head nods, eyebrow movements). This milestone is reached by maximizing audiovisual fidelity and the sense of copresence in all design elements, including physical layout, lighting, face tracking, multi-view capture, microphone array, multi-stream compression, loudspeaker output, and lenticular display. Our system achieves key 3D audiovisual cues (stereopsis, motion parallax, and spatialized audio) and enables the full range of communication cues (eye contact, hand gestures, and body language), yet does not require special glasses or body-worn microphones/headphones. The system consists of a head-tracked autostereoscopic display, high-resolution 3D capture and rendering subsystems, and network transmission using compressed color and depth video streams. Other contributions include a novel image-based geometry fusion algorithm, free-space dereverberation, and talker localization.
Author(s)/Presenter(s):

Q-zip: Singularity Editing Primitive for Quad Meshes
Abstract: Singularity editing of a quadrangle mesh consists in shifting singularities around for either improving the quality of the mesh elements or canceling extraneous singularities, so as to increase mesh regularity. However, the particular structure of a quad mesh renders the exploration of allowable connectivity changes non-local and hard to automate. In this paper, we introduce a simple, principled, and general quad-mesh editing primitive with which pairs of arbitrarily distant singularities can be efficiently displaced around a mesh through a deterministic and reversible chain of local topological operations with a minimal footprint. Dubbed Q-zip as it acts as a zipper opening up and collapsing down quad strips, our practical mesh operator for singularity editing can be easily implemented via parallel transport of a reference compass between any two irregular vertices. Batches of Q-zips performed in parallel can then be used for efficient singularity editing.
Author(s)/Presenter(s):
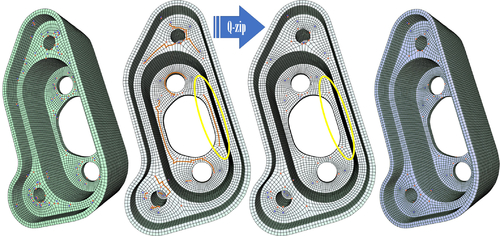
Rendering with Style: Combining Traditional and Neural Approaches for High-Quality Face Rendering
Abstract: For several decades, researchers have been advancing techniques for creating and rendering 3D digital faces, where a lot of the effort has gone into geometry and appearance capture, modeling and rendering techniques. This body of research work has largely focused on facial skin, with much less attention devoted to peripheral components like hair, eyes and the interior of the mouth. As a result, even with the best technology for facial capture and rendering, in most high-end productions a lot of artist time is still spent modeling the missing components and fine-tuning the rendering parameters to combine everything into photo-real digital renders. In this work we propose to combine incomplete, high-quality renderings showing only facial skin with recent methods for neural rendering of faces, in order to automatically and seamlessly create photo-realistic full-head portrait renders from captured data without the need for artist intervention. Our method begins with traditional face rendering, where the skin is rendered with the desired appearance, expression, viewpoint, and illumination. These skin renders are then projected into the latent space of a pre-trained neural network that can generate arbitrary photo-real face images (StyleGAN2). The result is a sequence of realistic face images that match the identity and appearance of the 3D character at the skin level, but is completed naturally with synthesized hair, eyes, inner mouth and surroundings. Notably, we present the first method for {\em multi-frame consistent} projection into this latent space, allowing photo-realistic rendering and preservation of the identity of the digital human over an animated performance sequence, which can depict different expressions, lighting conditions and viewpoints. Our method can be used in new face rendering pipelines and, importantly, in other deep learning applications that require large amounts of realistic training data with ground-truth 3D geometry, appearance maps, lighting, and viewpoint.
Author(s)/Presenter(s):

Reproducing Reality with a High-Dynamic-Range Multi-Focal Stereo Display
Abstract: With well-established methods for producing photo-realistic results, the next big challenge of graphics and display technologies is to achieve perceptual realism --- producing imagery indistinguishable from real-world 3D scenes. To deliver all necessary visual cues for perceptual realism, we built a High-Dynamic-Range Multi-Focal Stereo Display that achieves high resolution, accurate color, a wide dynamic range, and most depth cues, including binocular presentation and a range of focal depth. The display and associated imaging system have been designed to capture and reproduce a small near-eye three-dimensional object and to allow for a direct comparison between virtual and real scenes. To assess our reproduction of realism and demonstrate the capability of the display and imaging system, we conducted an experiment in which the participants were asked to discriminate between a virtual object and its physical counterpart. Our results indicate that the participants can only detect the discrepancy with a probability of 0.44. With such a level of perceptual realism, our display apparatus can facilitate a range of visual experiments that require the highest fidelity of reproduction while allowing for the full control of the displayed stimuli.
Author(s)/Presenter(s):

Repulsive Surfaces
Abstract: Geometric functionals that penalize bending or stretching of a surface play a key role in geometric modeling and digital geometry processing, but to date have ignored a very basic requirement: in many situations, surfaces must not pass through themselves. This paper develops a numerical framework for optimization of surface geometry while avoiding (self-)collision. The starting point is the tangent-point energy, which effectively pushes apart pairs of points that are close in space but distant along the surface. We develop a discretization of this energy for triangle meshes, and introduce a novel acceleration scheme based on a fractional Sobolev inner product. In contrast to similar schemes developed for curves, we avoid the complexity of building a multiresolution mesh hierarchy by decomposing our preconditioner into two ordinary Poisson equations, plus forward application of a fractional derivative. We further accelerate this scheme via hierarchical approximation, and describe how to incorporate a variety of constraints (area, volume, etc.). Finally, we explore how this machinery might be applied to applications in mathematical visualization and geometry processing.
Author(s)/Presenter(s):

Semi-supervised video-driven facial animation transfer for production
Abstract: We propose a simple algorithm for automatic transfer of facial expressions, from videos to a 3D character, as well as between distinct 3D characters through their rendered animations. Our method begins by learning a common, semantically-consistent latent representation for the different input image domains using an unsupervised image-to-image translation model. It subsequently learns, in a supervised manner, a linear mapping from the character images' encoded representation to the animation coefficients. At inference time, given the source domain (i.e., actor footage), it regresses the corresponding animation coefficients for the target character. Expressions are automatically remapped between the source and target identities despite differences in physiognomy. We show how our technique can be used in the context of markerless motion capture with controlled lighting conditions, for one actor and for multiple actors. Additionally, we show how it can be used to automatically transfer facial animation between distinct characters without consistent mesh parameterization and without engineered geometric priors. We compare our method with standard approaches used in production and with recent state-of-the-art models on single camera face tracking.
Author(s)/Presenter(s):

Ships, Splashes, and Waves on a Vast Ocean
Abstract: The simulation of large open water surface is challenging using a uniform volumetric discretization of the Navier-Stokes equations. Simulating water splashes near moving objects, which height field methods for water waves cannot capture, necessitates high resolutions. Such simulations can be carried out using the Fluid-Implicit-Particle (FLIP) method. However, the FLIP method is not efficient for the long-lasting water waves that propagate to long distances, which require sufficient depth for a correct dispersion relationship. This paper presents a new method to tackle this dilemma through an efficient hybridization of volumetric and surface-based advection-projection discretizations. We design a hybrid time-stepping algorithm that combines a FLIP domain and an adaptively remeshed Boundary Element Method (BEM) domain for the incompressible Euler equations. The resulting framework captures the detailed water splashes near moving objects with the FLIP method, and produces convincing water waves with correct dispersion relationships at modest additional costs.
Author(s)/Presenter(s):

SketchHairSalon: Deep Sketch-based Hair Image Synthesis
Abstract: Recent deep generative models allow real-time generation of hair images from sketch inputs. Existing solutions often require a user-provided binary mask to specify a target hair shape. This not only costs users extra labor but also fails to capture complicated hair boundaries. Those solutions usually encode hair structures via orientation maps, which, however, are not very effective to encode complex structures. We observe that colored hair sketches already implicitly define target hair shapes as well as hair appearance and are more flexible to depict hair structures than orientation maps. Based on these observations, we present SketchHairSalon, a two-stage framework for generating realistic hair images directly from freehand sketches depicting desired hair structure and appearance. At the first stage, we train a network to predict a hair matte from an input hair sketch, with an optional set of non-hair strokes. At the second stage, another network is trained to synthesize the structure and appearance of hair images from the input sketch and the generated matte. To make the networks in the two stages aware of long-term dependency of strokes, we apply self-attention modules to them. To train these networks, we present a new moderately large dataset, containing diverse hairstyles with annotated hair sketch-image pairs and corresponding hair mattes. Two efficient methods for sketch completion are proposed to automatically complete repetitive braided parts and hair strokes, respectively, thus reducing the workload of users. Based on the trained networks and the two sketch completion strategies, we build an intuitive interface to allow even novice users to design visually pleasing hair images exhibiting various hair structures and appearance via freehand sketches. The qualitative and quantitative evaluations show the advantages of the proposed system over the existing or alternative solutions.
Author(s)/Presenter(s):

Spatial-Temporal Motion Control via Composite Cam-follower Mechanisms
Abstract: Motion control, both on the trajectory and timing, is crucial for mechanical automata to perform functionalities such as walking and entertaining. We present composite cam-follower mechanisms that can control their spatialtemporal motions to exactly follow trajectories and timings specified by users, and propose a computational technique to model, design, and optimize these mechanisms. The building blocks of our mechanisms are a new kind of cam-follower mechanism with a modified joint, in which the follower can perform spatial motion on a planar, cylindrical, or spherical surface controlled by the 3D cam’s profile. We parameterize the geometry of these cam-follower mechanisms, formulate analytical equations to model their kinematics and dynamics, and present a method to combine multiple camfollower mechanisms into a working mechanism. Taking this modeling as a foundation, we propose a computational approach to designing and optimizing the geometry and layout of composite cam-follower mechanisms, with an objective of performing target spatial-temporal motions driving by a small motor torque. We demonstrate the effectiveness of our technique by designing different kinds of personalized automata and showing results not attainable by conventional mechanisms.
Author(s)/Presenter(s):
Spiral-Spectral Fluid Simulation
Abstract: We introduce a fast, expressive method for simulating fluids over radial domains, including discs, spheres, cylinders, ellipses, spheroids, and tori. We do this by generalizing the spectral approach of Laplacian Eigenfunctions, resulting in what we call spiral-spectral fluid simulations. Starting with a set of divergence-free analytical bases for polar and spherical coordinates, we show that their singularities can be removed by introducing a set of carefully selected enrichment functions. Orthogonality is established at minimal cost, viscosity is supported analytically, and we specifically design basis functions that support scalable FFT-based reconstructions. Additionally, we present an efficient way of computing all the necessary advection tensors. Our approach applies to both three-dimensional flows as well as their surface-based, co-dimensional variants. We establish the completeness of our basis representation, and compare against a variety of existing solvers.
Author(s)/Presenter(s):

Sum-of-Squares Geometry Processing
Abstract: Geometry processing presents a variety of difficult numerical problems, each seeming to require its own tailored solution. This breadth is largely due to the expansive list of geometric primitives, e.g., splines, triangles, and hexahedra, joined with an ever-expanding variety of objectives one might want to achieve with them. With the recent increase in attention toward higher-order surfaces, we can expect a variety of challenges porting existing solutions that work on triangle meshes to work on these more complex geometry types. In this paper, we present a framework for solving many core geometry processing problems on higher-order surfaces. We achieve this goal through sum-of-squares optimization, which transforms nonlinear polynomial optimization problems into sequences of convex problems whose complexity is captured by a single degree parameter. This allows us to solve a suite of problems on higher-order surfaces, such as continuous collision detection and closest point queries on curved patches, with only minor changes between formulations and geometries.
Author(s)/Presenter(s):
SuperTrack: Motion Tracking for Physically Simulated Characters using Supervised Learning
Abstract: In this paper we show how the task of motion tracking for physically simulated characters can be solved using supervised learning and optimizing a policy directly via back-propagation. To achieve this we make use of a world model trained to approximate a specific subset of the environment's transition function, effectively acting as a differentiable physics simulator through which the policy can be optimized to minimize the tracking error. Compared to popular model-free methods of physically simulated character control which primarily make use of Proximal Policy Optimization (PPO) we find direct optimization of the policy via our approach consistently achieves a higher quality of control in a shorter training time, with a reduced sensitivity to the rate of experience gathering, dataset size, and distribution.
Author(s)/Presenter(s):

Synthesizing Scene-Aware Virtual Reality Teleport Graphs
Abstract: We present a novel approach for synthesizing scene-aware virtual reality teleport graphs, which facilitate navigation in indoor virtual environments by suggesting desirable teleport positions. Our approach analyzes panoramic views at candidate teleport positions by extracting scene perception graphs, which encode scene perception relationships between the observer and the surrounding objects, and predict how desirable the views at these positions are. We train a graph convolutional model to predict the scene perception scores of different teleport positions. Based on such predictions, we apply an optimization approach to sample a set of desirable teleport positions while considering other navigation properties such as coverage and connectivity to synthesize a teleport graph. Using teleport graphs, users can navigate virtual environments efficaciously. We demonstrate our approach for synthesizing teleport graphs for common indoor scenes. By conducting a user study, we validate the efficacy and desirability of navigating virtual environments via the synthesized teleport graphs. We also extend our approach to cope with different constraints, user preferences, and practical scenarios.
Author(s)/Presenter(s):
TM-NET: Deep Generative Networks for Textured Meshes
Abstract: We introduce TM-NET, a novel deep generative model for synthesizing textured meshes in a part-aware manner. Once trained, the network can generate novel textured meshes from scratch or predict textures for a given 3D mesh, without image guidance. Plausible and diverse textures can be generated for the same mesh part, while texture compatibility between parts in the same shape is achieved via conditional generation. Specifically, our method produces texture maps for individual shape parts, each as a deformable box, leading to a natural UV map with minimal distortion. The network separately embeds part geometry (via a PartVAE) and part texture (via a TextureVAE) into their respective latent spaces, so as to facilitate learning texture probability distributions conditioned on geometry. We introduce a conditional autoregressive model for texture generation, which can be conditioned on both part geometry and textures already generated for other parts to achieve texture compatibility. To produce high-frequency texture details, our TextureVAE operates in a high-dimensional latent space via dictionary-based vector quantization. We also exploit transparencies in the texture as an effective means to model complex shape structures including topological details. Extensive experiments demonstrate the plausibility, quality, and diversity of the textures and geometries generated by our network, while avoiding inconsistency issues that are common to novel view synthesis methods.
Author(s)/Presenter(s):

Tessellation-Free Displacement Mapping for Ray Tracing
Abstract: Displacement mapping is a powerful tool for adding fine to medium geometric details over an existing surface. While GPU rasterization supports it through the hardware tessellation unit, ray tracing surface meshes textured with high quality displacement requires a significant amount of memory. More precisely, the input surface needs to be pre-tessellated at the displacement map resolution before being enriched with its mandatory acceleration data structure. Consequently, designing displacement maps interactively while enjoying a full physically-based rendering is often impossible, as simply tiling multiple times the map quickly saturates the graphics memory. In this work, we introduce a new tessellation-free displacement mapping approach for ray tracing. Our key insight is to decouple the displacement from its base domain by mapping a displacement-specific acceleration structures directly on the mesh. As a result, our method shows low memory footprint and fast high resolution displacement rendering, making possible to edit the displacement content interactively.
Author(s)/Presenter(s):

Time-Travel Rephotography
Abstract: Many historical people were only ever captured by old, faded, black and white photos, that are distorted due to the limitations of early cameras and the passage of time. This paper simulates traveling back in time with a modern camera to rephotograph famous subjects. Unlike conventional image restoration filters which apply independent operations like denoising, colorization, and superresolution, we leverage the StyleGAN2 framework to project old photos into the space of modern high-resolution photos, achieving all of these effects in a unified framework. A unique challenge with this approach is retaining the identity and pose of the subject in the original photo, while discarding the many artifacts frequently seen in low-quality antique photos. Our comparisons to current state-of-the-art restoration filters show significant improvements and compelling results for a variety of important historical people.
Author(s)/Presenter(s):

Transflower: probabilistic autoregressive dance generation with multimodal attention
Abstract: Dance requires skillful composition of complex movements that follow rhythmic, tonal and timbral features of music. Formally, generating dance conditioned on a piece of music can be expressed as a problem of modelling a high-dimensional continuous motion signal, conditioned on an audio signal. In this work we make two contributions to tackle this problem. First, we present a novel probabilistic autoregressive architecture that models the distribution over future poses with a normalizing flow conditioned on previous poses as well as music context, using a multimodal transformer encoder. Second, we introduce the currently largest 3D dance-motion dataset, obtained with a variety of motion-capture technologies, and including both professional and casual dancers. Using this dataset, we compare our new model against two baselines, via objective metrics and a user study, and show that both the ability to model a probability distribution, as well as being able to attend over a large motion and music context are necessary to produce interesting, diverse, and realistic dance that matches the music.
Author(s)/Presenter(s):
TreePartNet: Neural Decomposition of Point Clouds for 3D Tree Reconstruction
Abstract: We present TreePartNet, a neural network aimed at reconstructing tree geometry from point clouds obtained by scanning real trees. Our key idea is to learn a natural neural decomposition exploiting the assumption that a tree comprises locally cylindrical shapes. In particular, reconstruction is a two-step process. First, two networks are used to detect priors from the point clouds. One detects semantic branching points, and the other network is trained to learn a cylindrical representation of the branches. In the second step, we apply a neural merging module to reduce the cylindrical representation to a final set of generalized cylinders combined by branches. We demonstrate results of reconstructing realistic tree geometry for a variety of input models and with varying input point quality, e.g., noise, outliers, and incompleteness. We intensively evaluate our approach using data from both synthetic and real trees and comparing with alternative methods.
Author(s)/Presenter(s):

VR Social Copresence with Light Field Displays
Abstract: As virtual reality (VR) devices become increasingly commonplace, asymmetric interactions between people with and without headsets are becoming more frequent. Existing video pass-through VR headsets solve one side of these asymmetric interactions by showing the user a live reconstruction of the outside world. This paper further advocates for reverse pass-through VR, wherein a three-dimensional view of the user's face and eyes is presented to any number of outside viewers in a perspective-correct manner using a light field display. Tying together research in social telepresence and copresence, autostereoscopic displays, and facial capture, reverse pass-through VR enables natural eye contact and other important non-verbal cues in a wider range of interaction scenarios, providing a path to potentially increase the utility and social acceptability of VR headsets in shared and public spaces.
Author(s)/Presenter(s):

Volume decomposition for two-piece rigid casting
Abstract: We introduce a novel technique to automatically decompose an input object's volume into a set of parts that can be represented by two opposite height fields. Such decomposition enables the manufacturing of individual parts using two-piece reusable rigid molds. Our decomposition strategy relies on a new energy formulation that utilizes a pre-computed signal on the mesh volume representing the accessibility for a predefined set of extraction directions. Thanks to this novel formulation, our method allows to efficiently optimize for a fabrication-aware partitioning of volumes in a completely automatic way. We demonstrate the efficacy of our approach by generating valid volume partitionings for a wide range of complex objects and physically reproducing several of them.
Author(s)/Presenter(s):

Weatherscapes: Nowcasting Heat Transfer and Water Continuity
Abstract: Due to the complex interplay of various meteorological phenomena, simulating weather is a challenging and open research problem. In this contribution, we propose a novel physics-based model that enables simulating weather at interactive rates. By considering atmosphere and pedosphere we can define the hydrologic cycle – and consequently weather – in unprecedented detail. Specifically, our model captures different warm and cold clouds, such as mammatus, hole-punch, multi-layer, and cumulonimbus clouds as well as their dynamic transitions. We also model different precipitation types, such as rain, snow, and graupel by introducing a comprehensive microphysics scheme. The Wegener-Bergeron-Findeisen process is incorporated into our Kessler-type microphysics formulation covering ice crystal growth occurring in mixed-phase clouds. Moreover, we model the water run-off from the ground surface, the infiltration into the soil, and its subsequent evaporation back to the atmosphere. We account for daily temperature changes, as well as heat transfer between pedosphere and atmosphere leading to a complex feedback loop. Our framework enables us to interactively explore various complex weather phenomena. Our results are assessed visually and validated by simulating weatherscapes for various setups covering different precipitation events and environments, by showcasing the hydrologic cycle, and by reproducing common effects such as Foehn winds. We also provide quantitative evaluations creating high-precipitation cumulonimbus clouds by prescribing atmospheric conditions based on infrared satellite observations. With our model we can generate dynamic 3D scenes of weatherscapes with high visual fidelity and even nowcast real weather conditions as simulations by streaming weather data into our framework.
Author(s)/Presenter(s):