01. Character Simulation [Q&A Session]
-
 Full Access
Full Access
-
 Onsite Student Access
Onsite Student Access
-
 Virtual Full Access
Virtual Full Access
Date/Time: 06 – 17 December 2021
All presentations are available in the virtual platform on-demand.
Modeling Clothing as a Separate Layer for an Animatable Human Avatar
Abstract: We have recently seen great progress in building photorealistic animatable full-body codec avatars, but generating high-fidelity animation of clothing is still difficult. To address these difficulties, we propose a method to build an animatable clothed body avatar with an explicit representation of the clothing on the upper body from multi-view captured videos. We use a two-layer mesh representation to register each 3D scan separately with the body and clothing templates. In order to improve the photometric correspondence across different frames, texture alignment is then performed through inverse rendering of the clothing geometry and texture predicted by a variational autoencoder. We then train a new two-layer codec avatar with separate modeling of the upper clothing and the inner body layer. To learn the interaction between the body dynamics and clothing states, we use a temporal convolution network to predict the clothing latent code based on a sequence of input skeletal poses. We show photorealistic animation output for three different actors, and demonstrate the advantage of our clothed-body avatars over the single-layer avatars used in previous work. We also show the benefit of an explicit clothing model that allows the clothing texture to be edited in the animation output.
Author(s)/Presenter(s):
Donglai Xiang, Carnegie Mellon University, Facebook Reality Labs Research, United States of America
Fabian Prada, Facebook Reality Labs Research, United States of America
Timur Bagautdinov, Facebook Reality Labs Research, United States of America
Weipeng Xu, Facebook Reality Labs Research, United States of America
Yuan Dong, Facebook Reality Labs Research, United States of America
He Wen, Facebook Reality Labs Research, United States of America
Jessica Hodgins, Carnegie Mellon University, Facebook AI Research, United States of America
Chenglei Wu, Facebook Reality Labs Research, United States of America

Motion Recommendation for Online Character Control
Abstract: Reinforcement learning (RL) has been proven effective in many scenarios, including environment exploration and motion planning. However, its application in data-driven character control has produced relatively simple motion results compared to the recent approaches that use large complex motion data without RL. In this paper, we provide a real-time motion control method that can generate high-quality and complex motion results from various sets of unstructured data while retaining the advantage of using RL, which is the discovery of optimal behaviors by trial and error. We demonstrate the results of a character achieving different tasks, from simple direction control to complex avoidance of moving obstacles. Our system works equally well on biped/quadruped characters, with motion data ranging from 1 to 48 minutes, without any manual intervention. To achieve this, we exploit a finite set of discrete actions where each action represents the full-body future motion features. We first define a subset of actions that can be selected in each state and store these pieces of information in databases during the preprocessing step. The use of this subset of actions enables the effective learning of control policy even from a large motion data. To achieve interactive performance at run-time, we adopt a proposal network and a k-nearest neighbor action sampler.
Author(s)/Presenter(s):
Kyungmin Cho, Visual Media Lab, KAIST, South Korea
Chaelin Kim, Visual Media Lab, KAIST, South Korea
JungJin Park, Visual Media Lab, KAIST, South Korea
Joonkyu Park, Visual Media Lab, KAIST, South Korea
Junyong Noh, Visual Media Lab, KAIST, South Korea

PBNS: Physically Based Neural Simulation for Unsupervised Garment Pose Space Deformation
Abstract: We present a methodology to automatically obtain Pose Space Deformation (PSD) basis for rigged garments through deep learning. Classical approaches rely on Physically Based Simulations (PBS) to animate clothes. These are general solutions that, given a sufficiently fine-grained discretization of space and time, can achieve highly realistic results. However, they are computationally expensive and any scene modification prompts the need of re-simulation. Linear Blend Skinning (LBS) with PSD offers a lightweight alternative to PBS, though, it needs huge volumes of data to learn proper PSD. We propose using deep learning, formulated as an implicit PBS, to unsupervisedly learn realistic cloth Pose Space Deformations in a constrained scenario: dressed humans. Furthermore, we show it is possible to train these models in an amount of time comparable to a PBS of a few sequences. To the best of our knowledge, we are the first to propose a neural simulator for cloth. While deep-based approaches in the domain are becoming a trend, these are data-hungry models. Moreover, authors often propose complex formulations to better learn wrinkles from PBS data. Supervised learning leads to physically inconsistent predictions that require collision solving to be used. Also, dependency on PBS data limits the scalability of these solutions, while their formulation hinders its applicability and compatibility. By proposing an unsupervised methodology to learn PSD for LBS models (3D animation standard), we overcome both of these drawbacks. Results obtained show cloth-consistency in the animated garments and meaningful pose-dependant folds and wrinkles. Our solution is extremely efficient, handles multiple layers of cloth, allows unsupervised outfit resizing and can be easily applied to any custom 3D avatar.
Author(s)/Presenter(s):
Hugo Bertiche, Universitat de Barcelona; Computer Vision Center, UAB, Spain
Meysam Madadi, Computer Vision Center, UAB; Universitat de Barcelona, Spain
Sergio Escalera, Universitat de Barcelona; Computer Vision Center, UAB, Spain

SuperTrack: Motion Tracking for Physically Simulated Characters using Supervised Learning
Abstract: In this paper we show how the task of motion tracking for physically simulated characters can be solved using supervised learning and optimizing a policy directly via back-propagation. To achieve this we make use of a world model trained to approximate a specific subset of the environment's transition function, effectively acting as a differentiable physics simulator through which the policy can be optimized to minimize the tracking error. Compared to popular model-free methods of physically simulated character control which primarily make use of Proximal Policy Optimization (PPO) we find direct optimization of the policy via our approach consistently achieves a higher quality of control in a shorter training time, with a reduced sensitivity to the rate of experience gathering, dataset size, and distribution.
Author(s)/Presenter(s):
Levi Fussell, University of Edinburgh, Ubisoft Divertissements, United Kingdom
Kevin Bergamin, Ubisoft Divertissements, Canada
Daniel Holden, Ubisoft Divertissements, Canada

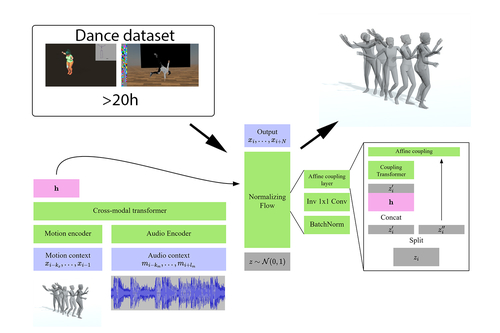
Transflower: probabilistic autoregressive dance generation with multimodal attention
Abstract: Dance requires skillful composition of complex movements that follow rhythmic, tonal and timbral features of music. Formally, generating dance conditioned on a piece of music can be expressed as a problem of modelling a high-dimensional continuous motion signal, conditioned on an audio signal. In this work we make two contributions to tackle this problem. First, we present a novel probabilistic autoregressive architecture that models the distribution over future poses with a normalizing flow conditioned on previous poses as well as music context, using a multimodal transformer encoder. Second, we introduce the currently largest 3D dance-motion dataset, obtained with a variety of motion-capture technologies, and including both professional and casual dancers. Using this dataset, we compare our new model against two baselines, via objective metrics and a user study, and show that both the ability to model a probability distribution, as well as being able to attend over a large motion and music context are necessary to produce interesting, diverse, and realistic dance that matches the music.
Author(s)/Presenter(s):
Guillermo Valle-Pérez, Inria, Ensta ParisTech, University of Bordeaux, France
Gustav Eje Henter, Division of Speech, Music and Hearing, KTH Royal Institute of Technology, Sweden
Jonas Beskow, Division of Speech, Music and Hearing, KTH Royal Institute of Technology, Sweden
Andre Holzapfel, Division of Media Technology and Interaction Design, KTH Royal Institute of Technology, Sweden
Pierre-Yves Oudeyer, Inria, Ensta ParisTech, University of Bordeaux, France
Simon Alexanderson, Division of Speech, Music and Hearing, KTH Royal Institute of Technology, Sweden